
Более органичный, постепенный подход к интеграции ИИ в существующие продукты
Делиться

Жизнь чат-бота обычно начинается одинаково. На совещании руководства кто-то говорит: «Давайте использовать ИИ!» Все кивают, энтузиазм нарастает, и, прежде чем вы успеваете оглянуться, все приходят к единому мнению: «Конечно, мы создадим чат-бота». Этот инстинкт понятен. Большие языковые модели мощны, вездесущи и увлекательны. Они обещают интуитивный доступ к универсальным знаниям и функциям.
Команда уходит и начинает разработку. Вскоре наступает время демонстрации. Появляется отточенный интерфейс чата, сопровождаемый уверенными аргументами о том, почему на этот раз всё будет иначе. Однако к этому моменту он обычно ещё не доходит до реальных пользователей в реальных ситуациях, и оценка становится предвзятой и оптимистичной. Кто-то из аудитории неизбежно задаёт свой вопрос, раздражая бота. Разработчики обещают исправить «это», но в большинстве случаев проблема носит системный характер.
Как только чат-бот появляется на рынке, первоначальный оптимизм часто сменяется разочарованием пользователей. Здесь всё становится немного личным, поскольку за последние недели мне пришлось потратить немало времени на общение с разными чат-ботами. Я обычно откладываю взаимодействие с поставщиками услуг до тех пор, пока ситуация не станет критически важной, и таких случаев накопилось несколько. Улыбающиеся виджеты чат-бота стали моей последней надеждой перед бесконечными звонками на горячую линию, но:
- Зайдя на сайт своей автостраховой компании, я попросил объяснить необъявленное повышение цен, но обнаружил, что у чат-бота нет доступа к моим данным о ценах. Всё, что он мог предложить, — это номер горячей линии. Ой!
- После отмены рейса в последнюю минуту я спросил чат-бота авиакомпании о причине. Он вежливо извинился, сказав, что, поскольку время вылета уже прошло, он не может мне помочь. Однако он был готов обсудить любые другие темы.
- На сайте одной телекоммуникационной компании я спросил, почему внезапно истёк срок действия моего тарифного плана. Чат-бот уверенно ответил, что не может комментировать вопросы, связанные с договором, и направил меня к разделу часто задаваемых вопросов. Как и ожидалось, ответы были длинными, но не по теме.
Эти взаимодействия не приблизили меня к решению и оставили меня на противоположном конце удовольствия. Чат-боты казались инородными телами. Они занимали место, замедляли работу и внимание, но не добавляли никакой ценности.
Давайте пропустим спор о том, являются ли эти системы преднамеренными тёмными паттернами. Дело в том, что устаревшие системы, подобные описанным выше, несут тяжёлое бремя энтропии. Они содержат огромное количество уникальных данных, знаний и контекста. В тот момент, когда вы пытаетесь интегрировать их с универсальным LLM, вы создаёте столкновение двух миров. Модель должна усвоить контекст вашего продукта, чтобы иметь возможность осмысленно рассуждать о вашей предметной области. Правильная разработка контекста требует навыков и времени для непрерывной оценки и итераций. И прежде чем вы доберётесь до этого момента, ваши данные должны быть готовы, но в большинстве организаций данные зашумлены, фрагментированы или просто отсутствуют.
В этой статье я подытожу идеи из моей книги «Искусство разработки продуктов на основе ИИ» и моего недавнего выступления на саммите Google Web AI, а также поделюсь более органичным, поэтапным подходом к интеграции ИИ в существующие продукты.
Использование меньших моделей для постепенной интеграции ИИ с низким уровнем риска
«При внедрении ИИ я вижу, что организации чаще терпят неудачу, начав слишком масштабно, чем начав слишком мелко». (Эндрю Нг).
Интеграция ИИ требует времени:
- Вашей технической команде необходимо подготовить данные и изучить доступные методы и инструменты.
- Вам необходимо создать прототип и провести итерации, чтобы найти наиболее выгодные позиции ИИ для вашего продукта и рынка.
- Пользователям необходимо калибровать свое доверие при переходе к новому вероятностному опыту.
Чтобы адаптироваться к этим кривым обучения, не стоит спешить с внедрением ИИ, особенно функций открытого чата, в работу пользователей. ИИ вносит неопределенность и ошибки, что не нравится большинству людей.
Один из эффективных способов ускорить внедрение ИИ в условиях уже существующих объектов — использовать малые языковые модели (МЯМ), которые обычно содержат от нескольких сотен миллионов до нескольких миллиардов параметров. Они гибко интегрируются с существующими данными и инфраструктурой вашего продукта, не добавляя дополнительных технологических издержек.
Как обучаются SLM
Большинство моделей SLM получаются из более крупных моделей посредством извлечения знаний. В этой конфигурации большая модель выступает в роли учителя, а меньшая — в роли ученика. Например, Gemini от Google служил учителем для Gemma 2 и Gemma 3, в то время как Llama Behemoth от Meta обучил множество более мелких моделей Llama 4. Подобно тому, как учитель-человек сжимает годы обучения в понятные объяснения и структурированные уроки, большая модель сжимает своё обширное пространство параметров в меньшее, более плотное представление, которое может усвоить ученик. В результате получается компактная модель, которая сохраняет большую часть компетенций учителя, но работает с гораздо меньшим количеством параметров и значительно меньшими вычислительными затратами.

Использование SLM
Одно из ключевых преимуществ SLM — гибкость развертывания. В отличие от LLM, которые в основном используются через внешние API, модели меньшего размера можно запускать локально, как в инфраструктуре вашей организации, так и непосредственно на устройстве пользователя:
- Локальное развертывание : вы можете размещать SLM на собственных серверах или в облачной среде, сохраняя полный контроль над данными, задержками и соответствием требованиям. Такая конфигурация идеально подходит для корпоративных приложений, где конфиденциальная информация или нормативные ограничения делают использование сторонних API нецелесообразным.
📈 Локальное развертывание также предлагает вам гибкие возможности тонкой настройки по мере сбора большего количества данных и необходимости реагировать на растущие ожидания пользователей.
- Развертывание на устройстве через браузер : современные браузеры обладают встроенными функциями искусственного интеллекта, на которые вы можете положиться. Например, Chrome интегрирует Gemini Nano через встроенные API искусственного интеллекта, а Microsoft Edge включает Phi-4 (см. документацию по Prompt API). Запуск моделей непосредственно в браузере обеспечивает низкую задержку и конфиденциальность в таких сценариях использования, как интеллектуальные текстовые подсказки, автозаполнение форм или контекстная справка.
Если вы хотите узнать больше о технических особенностях SLM, вот несколько полезных ресурсов:
- Обзор SLM и других типов языковых моделей: Липенкова, Жанна (2025). Искусство разработки продуктов ИИ, Глава 5: «Исследование и оценка языковых моделей».
- Сравнение современных моделей языка (SLM): Lu, Zhenyan и др. (2025). Малые языковые модели: обзор, измерения и выводы. Препринт доступен по адресу https://arxiv.org/pdf/2409.15790 arXiv
- Развёртывание и тонкая настройка SLM: Иоцциа, Гульельмо (2025). Малые языковые модели, ориентированные на предметную область.
Давайте теперь продолжим и посмотрим, что можно создать с помощью SLM, чтобы обеспечить ценность для пользователей и добиться устойчивого прогресса в интеграции ИИ.
Возможности продукта для SLM
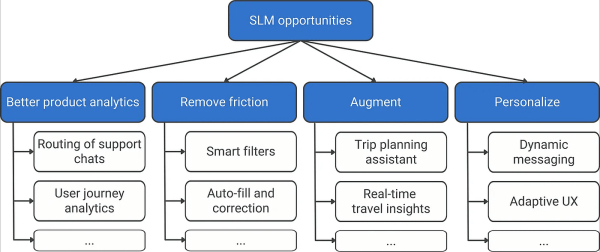
SLM-модели особенно эффективны в узкоспециализированных, чётко определённых задачах, где контекст и данные уже известны — в тех вариантах использования, которые глубоко заложены в существующих продуктах. Их можно рассматривать как специализированные встроенные интеллектуальные системы, а не как универсальных помощников. Давайте рассмотрим основные возможности, которые они открывают в условиях зрелости, как показано на следующем дереве возможностей.

1. Лучшая аналитика продукта
Прежде чем предоставлять пользователям функции ИИ, найдите способы улучшить свой продукт изнутри. Большинство продуктов уже генерируют непрерывный поток неструктурированного текста — чаты поддержки, запросы на помощь, отзывы внутри приложения. Менеджеры по управлению продуктом (SLM) могут анализировать эти данные в режиме реального времени и выявлять аналитические данные, которые влияют как на решения по продукту, так и на непосредственный пользовательский опыт. Вот несколько примеров:
- Отмечайте и маршрутизируйте чаты поддержки по мере их поступления, направляя технические проблемы соответствующим командам.
- Сигналы оттока клиентов регистрируются во время сеанса и требуют своевременного вмешательства.
- Предлагать релевантный контент или действия на основе текущего контекста пользователя.
- Выявляйте повторяющиеся точки сопротивления , пока пользователь все еще находится в процессе взаимодействия, а не спустя недели в ретроспективе.
Эти внутренние инструменты снижают риски, одновременно добавляя ценность и давая вашей команде время на обучение. Они укрепляют вашу базу данных и готовят вас к более заметным функциям ИИ, ориентированным на пользователя, в будущем.
2. Устраните трение
Затем сделайте шаг назад и проведите аудит уже имеющегося UX-долга. В стадии разработки большинство продуктов — не мечта дизайнера. Они были разработаны с учётом технических и архитектурных ограничений своего времени. Благодаря ИИ у нас появилась возможность снять некоторые из этих ограничений, уменьшив количество проблем и создав более быстрый и интуитивно понятный опыт взаимодействия.
Хорошим примером служат умные фильтры на поисковых сайтах, таких как Booking.com. Традиционно на таких страницах используются длинные списки флажков и категорий, призванные учесть все возможные предпочтения пользователей. Их неудобно проектировать и использовать, и в конечном итоге многие пользователи не могут найти нужную им настройку.
Фильтрация по языку меняет ситуацию. Вместо того, чтобы разбираться в сложной таксономии, пользователи просто вводят запрос (например, «отели рядом с пляжем, где разрешено проживание с домашними животными»), и модель автоматически преобразует его в структурированный запрос.

В более широком смысле, найдите области в вашем продукте, где пользователям необходимо применять вашу внутреннюю логику — категории, структуры или терминологию — и замените её взаимодействием на естественном языке. Когда пользователи могут напрямую выразить свои намерения, вы устраняете когнитивное сопротивление и делаете продукт более интеллектуальным и дружелюбным.
3. Увеличить
Упростив пользовательский опыт, пора подумать об аугментации — добавлении небольших, но полезных функций ИИ в ваш продукт. Вместо того, чтобы переосмысливать основной опыт, посмотрите, что пользователи уже делают с вашим продуктом — какие побочные задачи, обходные пути или внешние инструменты они используют для достижения своих целей. Могут ли специализированные модели ИИ помочь им делать это быстрее или эффективнее?
Например, приложение для путешествий может интегрировать генератор контекстных заметок о поездке, который обобщает детали маршрута или составляет черновики сообщений для попутчиков. Инструмент повышения производительности может включать генератор сводок встреч, который суммирует обсуждения или задачи из текстовых заметок без отправки данных в облако.
Эти функции органично вытекают из реального поведения пользователей и расширяют контекст вашего продукта, а не переопределяют его.
4. Персонализация
Успешная персонализация — это Святой Грааль искусственного интеллекта. Она переворачивает традиционную динамику: вместо того, чтобы просить пользователей учиться и адаптироваться к вашему продукту, ваш продукт теперь сам подстраивается под них, как идеально подобранная перчатка.
На начальном этапе сдерживайте амбиции — вам не нужен полностью адаптивный помощник. Вместо этого внесите небольшие, не сопряженные с риском изменения в то, что видят пользователи, как представлена информация или какие опции появляются первыми. На уровне контента ИИ может адаптировать тон и стиль, например, используя лаконичные формулировки для экспертов и более понятные формулировки для новичков. На уровне опыта он может создавать адаптивные интерфейсы. Например, инструмент управления проектами может предлагать наиболее релевантные действия («создать задачу», «поделиться обновлением», «сгенерировать сводку») на основе предыдущих рабочих процессов пользователя.
⚠️ Когда персонализация работает неправильно, доверие быстро подрывается . Пользователи чувствуют, что променяли личные данные на неприятный опыт. Поэтому внедряйте персонализацию только после того, как ваши данные будут готовы её поддерживать.
Почему «маленькие» победы со временем
Каждая успешная функция ИИ — будь то улучшение аналитики, удобная точка взаимодействия с пользовательским интерфейсом или персонализированный этап в более широком процессе — укрепляет вашу базу данных и развивает итеративную мощь вашей команды и уровень её ИИ-грамотности. Это также закладывает основу для более крупных и сложных приложений в будущем. Когда ваши «маленькие» функции работают надёжно, они становятся многоразовыми компонентами в более крупных рабочих процессах или модульных агентных системах (см. статью Nvidia «Малые языковые модели — будущее агентного ИИ»).
Подведем итог:
✅ Начните с малого — отдавайте предпочтение постепенному улучшению, а не разрушению.
✅ Экспериментируйте быстро — меньшие размеры моделей означают меньшие затраты и более быструю обратную связь.
✅ Будьте осторожны — начните с внутренних процессов; внедряйте ИИ, взаимодействующий с пользователем, только после того, как вы его проверите.
✅ Развивайте свой навык итераций — стабильный, комплексный прогресс важнее громких проектов.
Первоначально опубликовано на https://jannalipenkova.substack.com.
Источник: towardsdatascience.com





















