
Новый метод активного обучения для отбора высококачественных данных, который на порядки сокращает требования к обучающим данным для тонкой настройки LLM-моделей.
Классификация небезопасного рекламного контента оказалась привлекательной областью применения больших языковых моделей (БЛМ). Присущая сложность идентификации контента, нарушающего правила, требует решений, способных к глубокому контекстному и культурному пониманию, что является относительно сильной стороной БЛМ по сравнению с традиционными системами машинного обучения. Однако тонкая настройка БЛМ для таких сложных задач требует высококачественных обучающих данных, которые сложно и дорого обрабатывать в необходимом качестве и масштабе. Стандартные подходы к обучению моделей, требующие больших объемов данных, обходятся дорого, особенно с учетом необходимости учитывать изменение концепций по мере развития правил безопасности или появления новых типов небезопасного рекламного контента. В худшем случае модель необходимо переобучить на совершенно новом наборе данных. Поэтому сокращение объема необходимых обучающих данных имеет первостепенное значение.
С учетом этого, мы описываем новый масштабируемый процесс курирования для активного обучения, который может значительно сократить объем обучающих данных, необходимых для тонкой настройки моделей обучения с использованием линейных моделей, одновременно существенно улучшая соответствие модели мнению экспертов. Этот процесс может быть применен к наборам данных, содержащим сотни миллиардов примеров, для итеративного определения примеров, для которых аннотирование было бы наиболее ценным, а затем использования полученных экспертных меток для тонкой настройки.
В наших экспериментах нам удалось сократить объем необходимых обучающих данных со 100 000 до менее чем 500 примеров, одновременно повысив соответствие модели мнению экспертов до 65%. В производственных системах, использующих более крупные модели, наблюдалось еще большее сокращение объема данных: использовалось до четырех порядков меньше данных при сохранении или улучшении качества.
Процесс кураторства
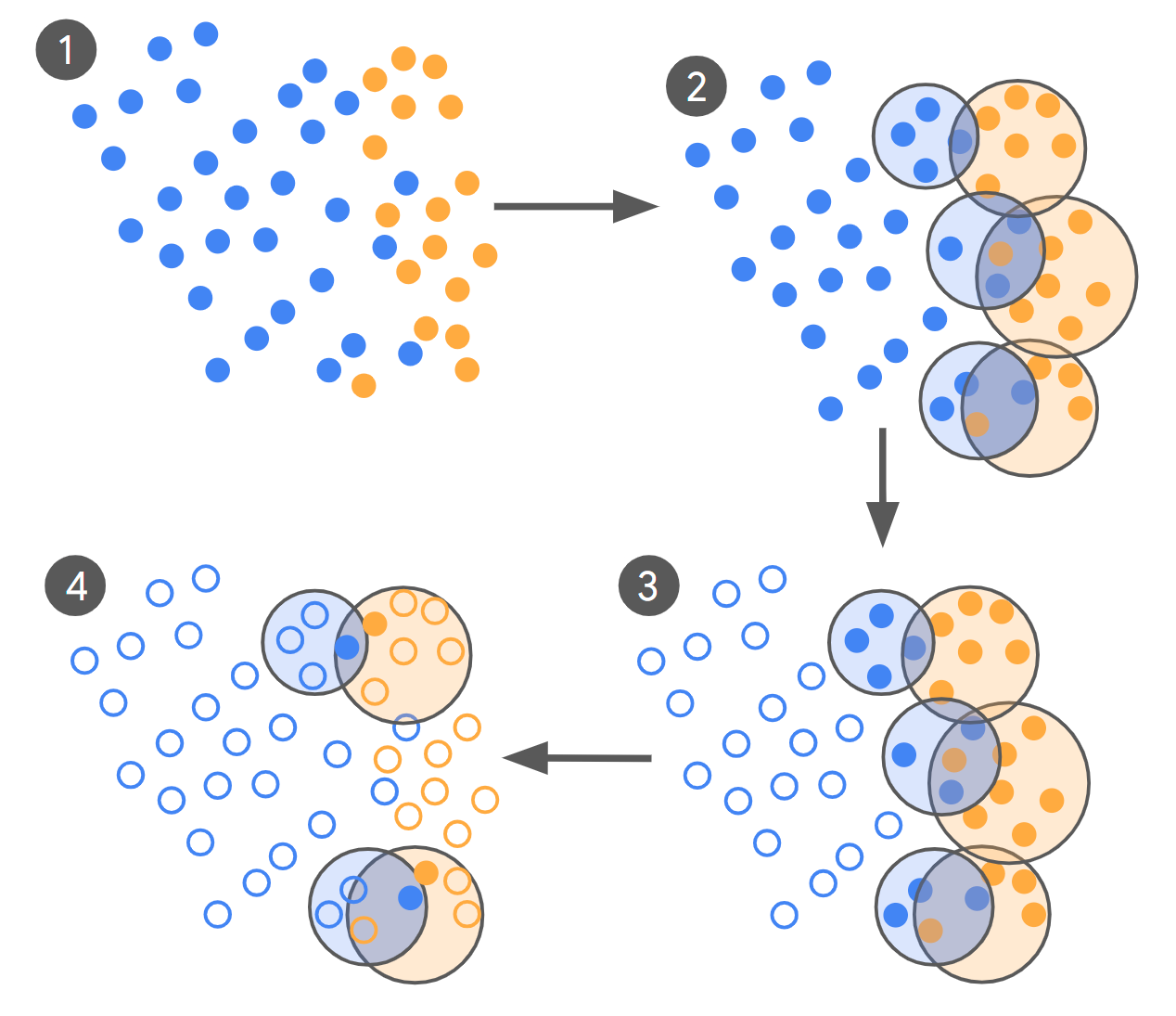
Наш процесс начинается с начальной модели с нулевым или малым количеством примеров (LLM-0), которой мы предоставляем запрос, описывающий интересующий нас контент, например, определяя кликбейт и спрашивая: «Является ли эта реклама кликбейтом?». Затем модель LLM-0 помечает рекламу как кликбейт (оранжевый цвет на рисунке ниже) или безобидную (синий цвет) и генерирует большой размеченный набор данных, показанный ниже (1) . Следует отметить, что этот начальный набор данных обычно сильно несбалансирован, поскольку в производственном трафике лишь очень немногие (<1%) объявления являются кликбейтом. Показатель истинно положительных результатов LLM также низок, поскольку она еще не была доработана. Чтобы найти наиболее информативные примеры, мы отдельно кластеризуем примеры, помеченные как кликбейт, и примеры, помеченные как безобидные, что приводит к некоторым перекрывающимся кластерам, указывая таким образом на потенциальную путаницу модели между примерами кликбейта и безобидными примерами (2) . Для каждой такой перекрывающейся пары кластеров мы находим пары примеров, расположенных ближе всего друг к другу, которые имеют разные метки (3) , и отправляем их экспертам для оценки. Если необходимо уложиться в бюджет обзора, мы отдаем приоритет парам примеров, которые охватывают большую область нашего пространства поиска (4) . Полученный набор является одновременно информативным (поскольку он содержит наиболее запутанные примеры вдоль границы принятия решения) и разнообразным (поскольку он включает в себя разные регионы вдоль этой границы принятия решения).

В процессе отбора предварительные метки генерируются с использованием модели LLM с небольшим количеством примеров, а затем каждый набор меток кластеризуется. Перекрывающиеся кластеры с различными метками используются для идентификации пар примеров, которые являются одновременно информативными и разнообразными.
Эти предоставленные экспертами метки случайным образом разделяются на два набора. Первый используется для оценки модели на основе двух ключевых показателей согласованности: внутренней согласованности, измеряющей степень согласия экспертов, и согласованности модели и экспертного мнения между текущей моделью и экспертами. Второй используется для тонкой настройки текущих моделей, что приводит к созданию следующей итерации модели. Процесс повторяется до тех пор, пока согласованность модели и экспертного мнения либо не совпадет с внутренней согласованностью, либо не стабилизируется и не станет невозможным для дальнейшего улучшения.
Метрическая система
Наш процесс отбора не предполагает существования эталонных данных. Многие задачи классификации в сфере безопасности рекламы, такие как модерация контента или обнаружение мошенничества, по своей природе неоднозначны и требуют интерпретации и обсуждения, даже среди экспертов в области политики. Поэтому мы не можем полагаться на стандартные метрики, такие как точность и полнота, которые требуют наличия эталонной метки. Вместо этого мы используем коэффициент Каппа Коэна, показатель того, насколько хорошо два независимых аннотатора согласуются друг с другом, превышая ожидаемое случайное совпадение. В наших экспериментах коэффициент Каппа Коэна используется как индикатор качества наборов данных (включая оценку модели в процессе отбора, как указано выше), так и как показатель производительности модели. Значения, близкие к 1, показывают более высокое соответствие, 0 указывает на отсутствие соответствия выше случайного, а отрицательные значения указывают на систематическое несоответствие. Хотя стандарты интерпретации этих показателей различаются, значения Каппа выше 0,8 широко считаются исключительно хорошими, а значения выше 0,4 обычно считаются приемлемыми.
Эксперименты
Мы хотели понять, какие модели и задачи больше всего выиграют от нашего процесса курирования. В качестве базовых моделей для наших экспериментов мы доработали две линейные модели обработки данных разного размера (Gemini Nano-1 с 1,8 млрд параметров и Nano-2 с 3,25 млрд параметров) на двух задачах разной сложности (более низкой и более высокой, на основе экспертной оценки) с использованием меток, полученных методом краудсорсинга. Каждый набор данных, полученный методом краудсорсинга, содержит около 100 тыс. аннотаций и характеризуется сильным дисбалансом классов, в среднем около 95% меток являются доброкачественными.
Мы сравнили каждое из этих четырех базовых условий с соответствующим условием , в котором каждая модель (Nano-1 и Nano-2) дорабатывалась в несколько этапов с использованием описанного выше процесса доработки. На каждой итерации мы выбирали наш набор примеров и использовали их для оценки и доработки модели, как описано выше. Все модели достигли плато, прежде чем сравнялись с внутренним выравниванием экспертов, поэтому мы остановились на 6 итерациях (~400 примеров для доработки и ~250 примеров для оценки) для задачи меньшей сложности и на 5 итерациях (~250 примеров для доработки и ~150 примеров для оценки) для задачи большей сложности. (Следует отметить, что в задаче меньшей сложности было большее разнообразие примеров, что может объяснить более длительное время, необходимое для сходимости.) В обоих наборах данных итоговый баланс классов составил ~40% положительных примеров.
В таблице ниже представлен обзор масштаба и качества данных, использованных в каждом условии. В процессе отбора эксперты достигли среднего парного коэффициента Каппа Коэна, равного 0,81 (для задачи меньшей сложности) и 0,78 (для задачи большей сложности). Мы считаем эти значения пределом производительности модели. Для оценки качества наших данных, полученных методом краудсорсинга, мы рассчитали коэффициент Каппа между аннотациями, полученными методом краудсорсинга, и оценками экспертов на основе нашего полного набора данных, полученных методом краудсорсинга, который составил 0,59 (меньшая сложность) и 0,41 (большая сложность).

Размер и качество наборов данных, использованных для наших базовых условий (с использованием данных, полученных методом краудсорсинга) и условий, отобранных экспертами (с использованием данных от экспертов). Номера наборов данных для наборов, отобранных экспертами, показывают суммарное количество образцов, собранных в процессе отбора как для тонкой настройки, так и для оценки модели; полный набор данных, отобранный экспертами, также служил набором данных для оценки на основе данных, полученных методом краудсорсинга. Качество наборов данных для оценки измеряется с помощью попарного коэффициента Каппа Коэна.
Ниже мы покажем, как модели, обученные на этих совершенно разных наборах данных, показали себя в каждом из наших базовых и обработанных условий. Модель с 1,8 млрд параметров продемонстрировала сопоставимую производительность в обеих задачах: базовая и обработанная модели имели выравнивание 0,24 и 0,25 соответственно для задачи меньшей сложности, и обе модели имели выравнивание 0,13 для задачи большей сложности. Напротив, модель с 3,25 млрд параметров показала значительное улучшение качества при обучении с использованием нашего процесса обработки данных. Показатели Каппа для базовой и обработанной моделей составили 0,36 и 0,56 соответственно для задачи меньшей сложности; и 0,23 и 0,38 соответственно для задачи большей сложности — улучшение выравнивания на 55-65% при использовании на три порядка меньшего количества данных (от 250 до 450 примеров по сравнению со 100 тыс. в базовом условии).

Эффективность моделей, обученных в специально подобранных и базовых условиях, измерялась как соответствие между ответами экспертов в предметной области и ответами моделей с использованием попарного коэффициента Каппа Коэна.

Наш метод отбора использует всего 250 (для задач более высокой сложности) и 450 (для задач более низкой сложности) обучающих выборок, оцененных парами экспертов (средний парный коэффициент Каппа Коэна 0,78 и 0,81). Базовые модели используют 100 000 обучающих выборок, полученных методом краудсорсинга (~5% положительных результатов).
Эти результаты демонстрируют, что тщательная обработка наборов данных LLM с целью сосредоточиться на меньшем количестве более информативных примеров может обеспечить лучшую или эквивалентную производительность классификатора при использовании гораздо меньшего количества данных — на три порядка меньше в экспериментах, описанных здесь, и до четырех порядков меньше для более крупных моделей, используемых в производстве. Конечно, для достижения таких результатов требуется не только качественная обработка данных, но и очень высокое качество самих данных. В наших примерах мы обнаружили, что для надежного превосходства над данными, полученными методом краудсорсинга, необходимо качество меток выше 0,8 попарного коэффициента Каппа Коэна. Последовательное достижение такого уровня качества представляет собой отдельную задачу, которая будет обсуждаться в последующей публикации в блоге.
Однако при достаточно высоком качестве меток наш процесс отбора позволяет использовать сильные стороны как моделей с низким качеством меток (LLM), способных охватить широкий спектр проблемных областей, так и экспертов в предметной области, которые могут более эффективно сосредоточиться на наиболее сложных примерах. Возможность переобучения моделей с использованием всего нескольких примеров особенно ценна для работы в быстро меняющихся условиях таких областей, как безопасность рекламы. Мы считаем, что описанный нами подход позволит системам, способным более гибко и эффективно использовать высококачественные метки, преодолеть проблему нехватки данных.
Благодарности
Эта работа была бы невозможна без нашей выдающейся команды инженеров и менеджеров по продуктам. Стив Уокер — соучредитель нашего проекта и соавтор процесса отбора контента, а также технический руководитель инфраструктуры машинного обучения нашего проекта. Келси МакЭлрой — менеджер по продуктам и соучредитель нашего проекта. Мы также хотим поблагодарить руководство Ads Privacy and Safety за их постоянную поддержку и веру в наше видение.
Источник: research.google