В новой статье NeurIPS 2025 показано, как самообучение с учителем обеспечивает ViT лучшее понимание изображений, чем контролируемое обучение.
Делиться

Новая статья лаборатории Конрада Кёрдинга [1] на конференции NeurIPS 2025 «Возникает ли естественным образом связывание объектов в больших предобученных визуальных преобразователях?» даёт представление о фундаментальном вопросе визуальной нейронауки: что требуется для связывания визуальных элементов и текстур в качестве объектов? Цель этой статьи — дать вам общее представление об этой проблеме, рассмотреть эту статью NeurIPS и, надеюсь, дать вам представление как об искусственных, так и о биологических нейронных сетях. Я также рассмотрю некоторые методы самообучения в глубоком обучении и визуальные преобразователи, а также подчеркну различия между современными системами глубокого обучения и нашим мозгом.
1. Введение
Когда мы рассматриваем сцену, наша визуальная система не просто передает нашему сознанию обобщенную сводку объектов и композиции; мы также получаем сознательный доступ ко всей визуальной иерархии.
Мы можем «захватить» объект, сосредоточив внимание на областях более высокого уровня, таких как нижняя височная кора (IT) и веретенообразная область лица (FFA), и получить доступ ко всем контурам и текстурам, которые закодированы в областях более низкого уровня, таких как V1 и V2.
Если бы у нас не было этой возможности доступа ко всей нашей визуальной иерархии, мы бы либо не имели осознанного доступа к низкоуровневым деталям зрительной системы, либо в высокоуровневых областях, пытающихся передать всю эту информацию, наблюдался бы взрывной рост размерности. Это потребовало бы значительного увеличения размеров нашего мозга и увеличения потребления энергии.
Такое распределение информации о визуальной сцене по всей зрительной системе означает, что компоненты или объекты сцены должны быть каким-то образом связаны между собой. Годами существовало две основные точки зрения на то, как это сделать: одна сторона утверждала, что связывание объектов использует нейронные колебания (или, в более общем смысле, синхронность) для связывания частей объекта, а другая – что усиления нейронной активности достаточно для связывания рассматриваемых объектов. Моё академическое образование однозначно относит меня к последнему лагерю, где я работаю под руководством Рюдигера фон дер Хейдта, Эрнста Нибура и Питера Рульфсемы.
Фон дер Мальсбург и Шнайдер предложили гипотезу связывания нейронных колебаний в 1986 году (см. обзор [2]), где они предположили, что каждый объект имеет свою собственную временную метку.
В этой модели, когда вы смотрите на картинку с двумя щенками, все нейроны зрительной системы, кодирующие первого щенка, будут активироваться в одной фазе колебаний, в то время как нейроны, кодирующие второго щенка, будут активироваться в другой фазе. Доказательства такого типа связи были обнаружены у кошек под наркозом, однако анестезия усиливает колебания в мозге.
В рамках модели частоты активации нейроны, кодирующие объекты, на которые направлено внимание, активировались с большей частотой, чем нейроны, кодирующие объекты, на которые не направлено внимание, а нейроны, кодирующие объекты, на которые направлено внимание, или объекты, на которые не направлено внимание, активировались с большей частотой, чем нейроны, кодирующие фон. Это было неоднократно и убедительно продемонстрировано на бодрствующих животных [3].
Первоначально было проведено больше экспериментов, подтверждающих гипотезы нейронной синхронности или осцилляций, но со временем появилось больше доказательств в пользу гипотезы связывания повышенной частоты импульсов.
В статье Ли основное внимание уделяется тому, демонстрируют ли модели глубокого обучения связывание объектов. Авторы убедительно доказывают, что сети ViT, обученные методом самообучения, естественным образом обучаются связыванию объектов, в то время как сети, обученные методом контролируемой классификации (ImageNet), — нет. Неспособность контролируемого обучения научить связыванию объектов, на мой взгляд, указывает на фундаментальную слабость метода однократного обратного распространения глобальной потери. Без тщательной настройки этой парадигмы обучения получается система, которая выбирает кратчайшие пути и (например) обучается текстурам вместо объектов, как показано Гейрхосом и др. [4]. В результате получаются модели, уязвимые к состязательным атакам и обучающиеся только тогда, когда это оказывает существенное влияние на итоговую функцию потерь. К счастью, самообучение работает достаточно хорошо в его нынешнем виде, без моих более радикальных подходов, и способно надежно обучаться связыванию объектов.
2. Методы
2.1 Архитектура: Vision Transformers (ViT)
В этом разделе я расскажу о Vision Transformer (ViT; [5]), поэтому можете пропустить этот раздел, если вам не нужно освежать знания об этой архитектуре. После его появления появилось множество других архитектур визуальных преобразователей, таких как Swin и различные гибридные сверточные преобразователи, такие как CoAtNet и Convolutional Vision Transformer (CvT). Тем не менее, исследовательское сообщество продолжает возвращаться к ViT. Отчасти это связано с тем, что ViT хорошо подходит для современных самоконтролируемых подходов, таких как Masked Auto-Encoding (MAE) и I-JEPA (Image Joint Embedding Predictive Architecture).

ViT разбивает изображение на сетку фрагментов, которые преобразуются в токены. В ViT токены — это просто векторы признаков, в то время как в других преобразователях токены могут быть дискретными. В статье Ли авторы уменьшили размер изображений до (224×224) пикселей, а затем разбили их на сетку из (16×16) фрагментов ((14×14) пикселей на фрагмент). Затем фрагменты преобразуются в токены простым сглаживанием.
Позиции патчей на изображении добавляются как позиционные вложения с использованием поэлементного сложения. Для классификации к последовательности токенов добавляется специальный, обученный токен классификации. Таким образом, если имеется (W times H) патчей, то имеется (1 + W times H) входных токенов. Также имеется (1 + W times H) выходных токенов из базовой модели ViT. Первый токен выходной последовательности, соответствующий токену классификации, передаётся в начало классификации для выполнения классификации. Все остальные выходные токены игнорируются в задаче классификации. В процессе обучения сеть учится кодировать глобальный контекст изображения, необходимый для классификации, в этот токен.
Токены проходят через кодер преобразователя, сохраняя при этом длину последовательности. Существует подразумеваемое соответствие между входным токеном и тем же токеном во всей сети. Хотя нет гарантии, что именно будут кодировать токены в середине сети, на это может повлиять метод обучения. Плотная задача, такая как MAE, обеспечивает это соответствие между i-м токеном входной последовательности и i-м токеном выходной последовательности. Задача с грубым сигналом, например, классификация, может не научить сеть поддерживать это соответствие.
2.2. Режимы обучения: самообучение под наблюдением (SSL)
Чтобы оценить результаты, не обязательно знать подробности методов самообучения, использованных в статье Ли и др. на конференции NeurIPS 2025. Авторы утверждают, что результаты применимы ко всем протестированным ими методам SSL: DINO, MAE и CLIP.
DINOv2 был первым методом SSL, протестированным авторами, и именно на нём они сосредоточились. DINO работает, снижая качество изображения с помощью кадрирования и дополнения данных. Основная идея заключается в том, что модель обучается извлекать важную информацию из деградировавших данных и сопоставлять её с полным исходным изображением. Сложность заключается в наличии обучающей сети, которая представляет собой экспоненциальное скользящее среднее (EMA) обучающей сети. Вероятность её разрушения ниже, чем при использовании обучающей сети для генерации обучающего сигнала.
MAE — это разновидность моделирования маскированных изображений (MIM). Он удаляет определённый процент токенов или фрагментов из входной последовательности. Поскольку токены содержат позиционное кодирование, это легко сделать. Этот сокращённый набор токенов затем пропускается через кодер. Затем токены проходят через декодер-трансформер, чтобы попытаться «дорисовать» недостающие токены. Сигнал потери затем получается путём сравнения входных данных со всеми токенами (истина) и предсказанными токенами.
CLIP использует изображения с подписями, например, взятые из интернета. Он объединяет кодировщик текста и кодировщик изображений, обучая их одновременно. Я не буду тратить много времени на описание этого процесса, но стоит отметить, что этот обучающий сигнал является грубым (основан на всём изображении и всей подписи). Обучающие данные масштабируются по всему интернету, а не ограничиваются ImageNet, и, хотя сигнал грубый, векторы признаков не являются разреженными (например, кодируются методом прямого кодирования). Таким образом, хотя он считается самообучаемым, он использует слабо контролируемый сигнал в виде подписей.
2.3. Зонды

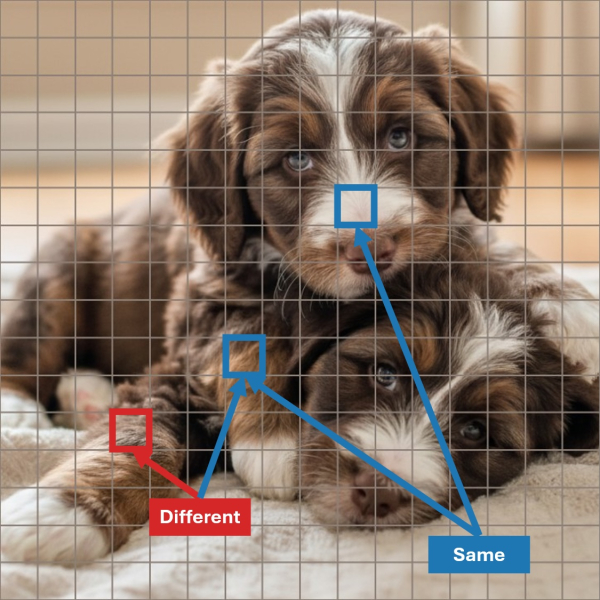
Как показано на рисунке 2, зонд или тест, способный различать связывание объектов, должен определить, принадлежат ли синие пятна одному и тому же щенку, а красные и синие пятна — разным щенкам. Таким образом, вы можете создать тест, например, на косинусное сходство между пятнами, и обнаружить, что он довольно хорошо справляется с вашим тестовым набором. Но… действительно ли он обнаруживает связывание объектов, а не низкоуровневые или основанные на классах признаки? Большинство изображений, вероятно, не такие сложные. Поэтому вам нужен какой-то зонд, например, тест на косинусное сходство, но также и некая сильная базовая линия, способная, например, определить, принадлежат ли пятна одному и тому же семантическому классу, но не обязательно принадлежат ли они одному и тому же экземпляру.
Наиболее близкими к косинусному сходству являются диагональный квадратичный зонд и квадратичный зонд , где последний, по сути, добавляет ещё один линейный слой (что-то вроде линейного зонда, но у вас есть два линейных зонда, которые затем скалярно умножаются). Именно эти два зонда, на мой взгляд, потенциально способны обнаруживать связывание. У них также есть несколько зондов, основанных на классах объектов, которые я бы назвал сильными базовыми линиями.

На их рисунке 2 (моём рисунке 3) я бы обратил внимание на пурпурную кривую квадратичного зонда и оранжевую кривую перекрывающегося класса объекта. Квадратичная кривая не поднимается выше кривых класса объекта до слоёв 10–11 из 23. Диагональная квадратичная кривая никогда не поднимается выше этих кривых (см. исходный рисунок в статье), что означает, что для проецирования информации о связывании в подпространство «IsSameObject» требуется как минимум линейный слой.
Более подробно о зондах я расскажу в приложении, которое рекомендую пропустить, пока вы не прочтете статью.
3. Центральное утверждение: Ли и др. (2025)
Основное утверждение их статьи заключается в том, что модели ViT, обученные с помощью самообучения с учителем (SSL), естественным образом усваивают связывание объектов, в то время как модели ViT, обученные с помощью классификации с учителем ImageNet, демонстрируют гораздо более слабое связывание объектов. В целом, я считаю их аргументы убедительными, хотя, как и во всех статьях, есть области, где их можно было бы улучшить.
Их аргументы ослабляются использованием слабой базовой линии, заключающейся в постоянном предположении, что два фрагмента не связаны, как показано на рисунке 2. К счастью, они использовали широкий спектр тестов, включая более сильные базовые линии на основе классов, и их квадратичный тест всё равно работает лучше. Я действительно считаю, что можно было бы создать лучший тест и/или базовые линии, например, добавив позиционную осведомлённость в методы на основе классов. Однако я считаю, что это придирка, и объектно-ориентированные тесты действительно представляют собой довольно хорошую базовую линию. Их рисунок 4 даёт дополнительную уверенность в том, что он выполняет связывание объектов, хотя расстояние между тестами всё ещё может играть роль.
Их контролируемая модель ViT достигла точности всего на 3,7% выше, чем слабая базовая модель, что я бы интерпретировал как отсутствие какой-либо привязки к объектам. Этот результат осложняется тем, что модели, обученные с помощью DINOv2 (и MAE), обеспечивают соответствие между входными и выходными токенами, в то время как классификация ImageNet обучается только на первом токене, соответствующем изученному токену задачи «классификация»; остальные выходные токены игнорируются этой потерей контролируемого обучения. Таким образом, зонд предполагает, что (i)-й токен на заданном уровне соответствует (i)-му токену входной последовательности, что, вероятно, более верно для моделей, обученных с помощью DINOv2, чем для модели классификации, обученной с помощью ImageNet.
Думаю, остаётся открытым вопрос, продемонстрировали бы CLIP и MAE связывание объектов при сравнении с более сильным базовым уровнем. На рисунке 7 в Приложении сигнал связывания CLIP не выглядит таким уж сильным. Хотя CLIP, как и обучение классификации с учителем, не обеспечивает соответствия токенов на протяжении всей обработки. В частности, как в обучении с учителем, так и в CLIP слой с пиковой точностью предсказания того же объекта находится раньше в сети (0,13 и 0,39 из 1), в то время как сети, сохраняющие соответствие токенов, показывают пик позже (0,65–1 из 1).
Возвращаясь к «мягкому» биологическому мозгу, одна из причин, по которой связывание представляет собой проблему, заключается в том, что представление объекта распределено по всей визуальной иерархии. Архитектура ViT принципиально отличается тем, что в ней отсутствует двунаправленность информации; вся информация движется в одном направлении, и представление на нижних уровнях больше не требуется после передачи информации. Приложение A3 показывает, что квадратичный зонд обладает относительно высокой точностью оценки связывания участков из слоёв 15 и 18, поэтому, по всей видимости, эта информация, по крайней мере, присутствует, даже если это не двунаправленная рекуррентная архитектура.
4. Заключение: новая основа для «понимания»?
Я думаю, что эта статья действительно очень крутая, так как это первая известная мне статья, которая демонстрирует доказательство модели глубокого обучения, демонстрирующей эмерджентное свойство связывания объектов. Было бы здорово, если бы результаты других методов SSL, таких как MAE, можно было бы показать с более сильными базовыми показателями, но эта статья, по крайней мере, приводит убедительные доказательства того, что ViT, обученные с помощью DINO, демонстрируют связывание объектов. Предыдущие исследования предполагали, что это не так. Слабость (или отсутствие) сигнала связывания объектов от ViT, обученных с помощью классификации ImageNet, также интересна и согласуется с работами, которые предполагают, что CNN, обученные с помощью классификации ImageNet, смещены в сторону текстуры, а не формы объекта [4], хотя ViT имеют меньшее смещение текстуры [6], а самоконтроль DINO также снижает смещение текстуры (но, возможно, не MAE) [7].
Всегда есть вещи, которые можно улучшить с помощью научных работ, и именно поэтому наука и исследования опираются на прошлые исследования, расширяют и проверяют предыдущие результаты. Отделить объектную привязку от других признаков сложно и может потребовать тестов, таких как искусственные геометрические стимулы, чтобы с уверенностью доказать, что объектная привязка была обнаружена без каких-либо сомнений. Тем не менее, представленные доказательства всё ещё достаточно убедительны.
Даже если вас не интересует сам процесс связывания объектов, разница в поведении ViT, обученных с помощью неконтролируемого и контролируемого обучения, довольно разительна и даёт нам некоторое представление о режимах обучения. Это говорит о том, что базовые модели, которые мы создаём, обучаются способом, более близким к золотому стандарту настоящего интеллекта: человеку.
Ссылки
- Рецензии NeurIPS: https://openreview.net/forum?id=5BS6gBb4yP
- Код: https://github.com/liyihao0302/vit-object-binding
- https://kording.substack.com/
Приложение
Подробности зонда
Я добавляю этот раздел в качестве приложения, поскольку он может быть полезен, если вы собираетесь более подробно изучить статью. Однако, подозреваю, что для большинства читателей этого поста он будет слишком подробным. Одним из подходов к определению того, связаны ли два токена, может быть вычисление их косинусного сходства. Это простое скалярное произведение векторных токенов, нормализованных по L2. К сожалению, по моему мнению, авторы не пытались использовать нормализацию векторных токенов по L2, но попробовали взвешенное скалярное произведение, которое они называют диагональным квадратичным зондом .
$$phi_text{diag} (x,y) = x ^ topmathrm{diag} (w) y$$
Веса ( w ) запоминаются, поэтому зонд может научиться фокусироваться на измерениях, более важных для связывания. Хотя нормализация уровня L2 не проводилась, к токенам была применена послойная нормализация, включающая нормализацию уровня L1 и отбеливание для каждого токена.
Нет оснований полагать, что свойство привязки объекта будет хорошо выделено в векторах признаков в их текущем виде, поэтому имеет смысл сначала спроецировать их в новое подпространство «IsSameObject», а затем вычислить их скалярное произведение. Вот квадратичный зонд , который, как выяснилось, работает так хорошо:
$$begin{align}
phi_text{quad} (x,y) &= W x cdot W y \
&= left( W x right) ^ top W y \
&= x ^top W ^top W y
end{align}
$$
где (W in mathbb R ^{k times d}, k ll d).
Квадратичный зонд гораздо лучше справляется с извлечением информации о связывании, чем диагональный квадратичный зонд. Более того, я бы сказал, что квадратичный зонд — единственный из показанных зондов, способный извлечь информацию о том, связаны ли объекты, поскольку он единственный, превосходящий сильный базовый уровень зондов, основанных на классах объектов.
Я пропустил их линейный зонд, который, как мне кажется, они должны были включить в статью, но это не имеет никакого смысла. Для этого они применили линейный зонд (дополнительный слой, который обучается отдельно) к обоим токенам, а затем сложили результаты. Именно сложение, на мой взгляд, и является причиной того, что зонд отвлекает. Для сравнения токенов необходимо умножение. Квадратичный зонд — лучший эквивалент линейного зонда при сравнении двух векторов признаков.
Библиография
[1] Y. Li, S. Salehi, L. Ungar и KP Kording, Возникает ли естественным образом связывание объектов в больших предварительно обученных преобразователях зрения? (2025), препринт arXiv arXiv:2510.24709
[2] PR Roelfsema, Решение проблемы связывания: ансамбли формируются, когда нейроны увеличивают частоту своей активности — им не нужно колебаться или синхронизироваться (2023), Neuron, 111(7), 1003-1019
[3] Дж. Р. Уиллифорд и Р. фон дер Хейдт, Кодирование пограничной собственности (2013), журнал Scholarpedia, 8 (10), 30040.
[4] Р. Гейрхос, П. Рубиш, К. Михаэлис, М. Бетге, Ф. А. Вихманн и В. Брендель, Обученные с помощью ImageNet сверточные нейронные сети смещены в сторону текстуры; увеличение смещения формы повышает точность и надежность (2018), Международная конференция по обучению представлениям
[5] А. Досовицкий, Л. Бейер, А. Колесников, Д. Вайссенборн, Х. Чжай, Т. Унтертинер и др., Изображение стоит 16×16 слов: Трансформаторы для распознавания изображений в масштабе (2020), препринт arXiv arXiv:2010.11929
[6] М.М. Насир, К. Ранасингхе, С.Х. Хан, М. Хаят, Ф. Шахбаз Хан и М.Х. Янг, Интригующие свойства преобразователей зрения (2021), Достижения в области нейронных систем обработки информации, 34, 23296-23308
[7] Н. Парк, В. Ким, Б. Хо, Т. Ким и С. Юн, Чему учатся самоконтролируемые преобразователи зрения? (2023), препринт arXiv arXiv:2305.00729
Источник: towardsdatascience.com