
Мы представляем новый подход к прогнозированию временных рядов, который использует непрерывное предварительное обучение для того, чтобы научить базовую модель временных рядов адаптироваться к контекстным примерам во время вывода.
Быстрые ссылки
- Бумага
- Делиться
Прогнозирование временных рядов имеет важное значение для современного бизнеса, помогая прогнозировать все — от потребностей в запасах до спроса на энергию. Традиционно это подразумевало создание отдельной специализированной модели для каждой задачи — процесс, который является медленным и требует значительной экспертизы.
Появление обучения без примеров (zero-shot learning) предложило решение. Наша предыдущая модель, TimesFM, представляла собой предварительно обученную базовую модель, которая могла точно прогнозировать без специальной подготовки. Но что, если несколько примеров могли бы сделать прогноз еще лучше? Например, прогнозирование дорожного движения на автомагистралях было бы точнее, если бы модель учитывала данные с других близлежащих автомагистралей или с той же автомагистрали несколько недель назад. Стандартное решение, контролируемая тонкая настройка (surveyed fine tuneing), которая использует тщательно отобранные данные для тонкой настройки существующей модели, вновь вносит сложность, которой, как надеются специалисты, следует избегать при обучении без примеров.
В нашей новой работе «Тонкая настройка моделей временных рядов в контексте», представленной на ICML 2025, мы предлагаем новый подход, который преобразует TimesFM в модель обучения с небольшим количеством примеров. Этот метод использует непрерывное предварительное обучение, чтобы научить модель учиться на небольшом количестве примеров во время вывода. В результате мы получаем мощную новую возможность, которая соответствует производительности контролируемой тонкой настройки без необходимости дополнительного сложного обучения со стороны пользователя.

Подобно модели LLM с использованием небольшого количества примеров ( слева ), базовая модель временных рядов должна поддерживать использование небольшого количества примеров с произвольным числом связанных примеров временных рядов в контексте ( справа ). Оранжевая рамка заключает входные данные для моделей.
Перепроектирование модели
TimesFM — это модифицированный декодер, который токенизирует каждые 32 смежных временных точки (патч) в качестве входного токена и применяет стек преобразователей поверх последовательности входных токенов для генерации выходных токенов. Затем он применяет общий многослойный персептрон (MLP) для преобразования каждого выходного токена обратно во временной ряд из 128 временных точек.
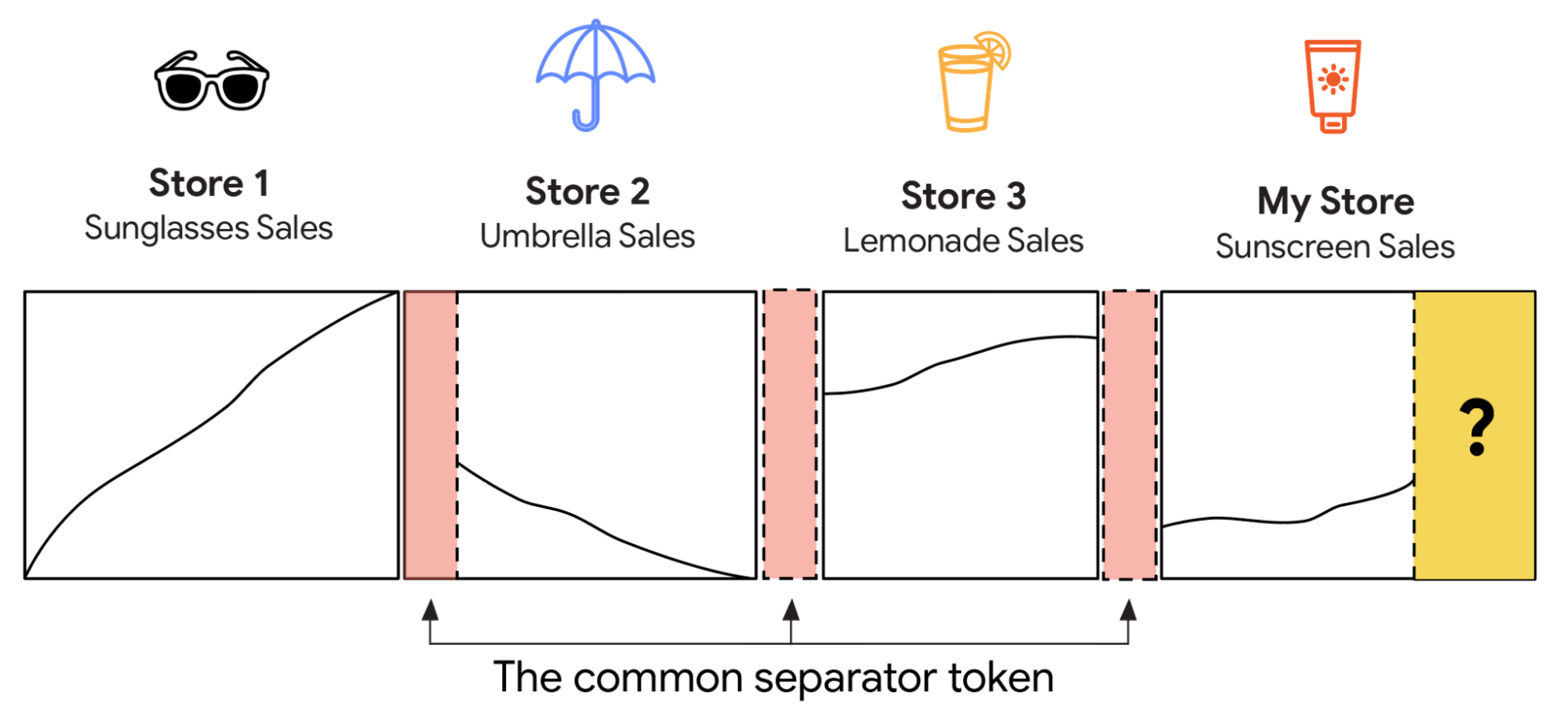
Для создания TimesFM-ICF (In-Context Fine-tuning) мы начинаем с базовой модели TimesFM и продолжаем предварительное обучение с новым контекстом: историей прогнозов плюс все примеры из контекста. Первый шаг — убедиться, что модель не путает историю прогнозов и примеры из контекста. Представьте, что вы даете модели список чисел, представляющих несколько разных вещей, например, данные о продажах солнцезащитных очков в одном магазине, а затем данные о продажах зонтов в другом. Если вы просто объедините все эти числа, модель может запутаться, приняв их за один непрерывный поток данных. Например, если продажи в первом магазине росли, а продажи во втором — падали, модель может ошибочно воспринять это как единый восходящий/нисходящий тренд, а не как два отдельных, простых тренда.
Чтобы это исправить, мы добавляем специальный, обучаемый «общий разделительный токен» — своего рода цифровой «знак остановки» или символ «нового абзаца» — после каждого набора чисел. Благодаря этим разделителям, как только модель обратит внимание на разделительный токен примера, который она уже видела, она не перепутает его с данными, которые она в данный момент пытается спрогнозировать. Теоретически это позволяет модели учиться на закономерностях в этих прошлых примерах и применять эти знания к текущему прогнозу. Например, модель может узнать, что «все продажи в магазине в последнее время демонстрируют устойчивые, направленные тенденции, поэтому я должен прогнозировать восходящую тенденцию для продаж солнцезащитного крема в моем новом магазине».

Объединение контекстных примеров без разделителей может запутать модель — множественные монотонные тренды могут выглядеть как рваный, непрерывный узор, если их объединить наивно.
Поскольку разделительные токены и механизм внимания к ним являются новыми для TimesFM, наш второй шаг включает в себя продолжение предварительного обучения базовой модели TimesFM, чтобы научить её новым особенностям. Рецепт здесь довольно прост: мы создали новый набор данных, включающий как контекстные примеры, так и разделительные токены, и применили стандартное обучение прогнозированию следующего токена только с помощью декодера. Входные данные передаются в слой MLP, который генерирует токены. Они передаются в слой причинного самовнимания (CSA), который «обращает внимание» на информацию от предыдущих токенов в последовательности — шаг, который имеет решающее значение в таких задачах, как прогнозирование временных рядов, поскольку он предотвращает заглядывание модели в будущее. Затем CSA подаёт данные в сеть прямого распространения (FFN). Мы повторяем CSA и FFN несколько раз (т.е., стековые трансформеры), прежде чем подключить результат к выходному слою MLP.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
TimesFM-ICF использует архитектуру, основанную только на декодере, для прогнозирования временных рядов с использованием контекстных примеров. Для различения контекстных примеров и истории задачи введен специальный общий разделительный токен.
Тестирование модели
Мы оценили TimesFM-ICF на 23 наборах данных, которые модель никогда не видела ни на одном этапе обучения. Каждый набор данных в этом бенчмарке содержит несколько временных рядов. При прогнозировании временного ряда мы начинаем с его непосредственной истории, затем выбираем последовательности из его полной истории и историй других временных рядов в том же наборе данных в качестве контекстных примеров. Это гарантирует релевантность контекстных примеров и отсутствие утечки информации.
На диаграмме ниже показано агрегирование геометрического среднего (GM) средних абсолютных масштабированных ошибок (MASE), нормализованных с помощью простого повторения последнего сезонного паттерна. Здесь мы сосредоточимся на двух базовых уровнях:
- TimesFM (Base) — это предварительно обученная модель, с которой мы начали.
- TimesFM-FT — это TimesFM (Base) с контролируемой тонкой настройкой, использующая разделение обучающей выборки для каждого набора данных, а затем оцениваемая на соответствующей тестовой выборке. Это надежная базовая модель, отражающая ранее лучшие практики адаптации предметной области.

TimesFM-ICF улучшает производительность TimesFM (Base) по сравнению со многими моделями, предназначенными для решения конкретных задач, и достигает той же производительности, что и TimesFM-FT, которая представляет собой версию TimesFM, доработанную для каждого конкретного набора данных.
TimesFM-ICF на 6,8% точнее, чем TimesFM (Base). Что еще более удивительно и вдохновляет, так это то, что он соответствует производительности TimesFM-FT без необходимости проведения контролируемой тонкой настройки.
Помимо повышения точности, TimesFM-ICF демонстрирует и другие желаемые свойства. Например, это согласуется с нашими ожиданиями, что при большем количестве контекстных примеров модель будет делать более точные прогнозы за счет увеличения времени вывода. Кроме того, TimesFM-ICF демонстрирует лучшее использование контекста по сравнению с моделью, работающей исключительно с длинным контекстом и не имеющей возможности работать с контекстными примерами.
Будущее: более доступное и эффективное прогнозирование
Этот новый подход имеет значительные практические применения, поскольку позволяет предприятиям развертывать более надежную и адаптируемую единую мощную модель прогнозирования. Вместо запуска полноценного проекта машинного обучения для новых задач, таких как прогнозирование спроса на новый продукт, они могут просто передать модели несколько новых релевантных примеров. Это немедленно обеспечивает получение современных специализированных прогнозов, значительно сокращая затраты, ускоряя принятие решений и инновации, а также демократизируя доступ к высококачественному прогнозированию.
Мы с оптимизмом смотрим в будущее этого исследования, особенно в разработку автоматизированных стратегий для выбора наиболее релевантных контекстных примеров. Делая базовые модели более интеллектуальными и адаптивными, мы даем большему числу пользователей возможность принимать более обоснованные решения на основе данных.
Благодарности
Это исследование проводилось под руководством тогдашнего студента-исследователя Мэтью Фоу в сотрудничестве с коллегами из Google Research Абхиманью Дасом и Иваном Кузнецовым. Создание этой статьи стало возможным благодаря огромной помощи редакторов Марка Симборга и Кимберли Шведе.
Источник: research.google