Использование ускорения на GPU для ускорения байесовского вывода с месяцев до минут…
Делиться

Медленное время вычислений мешает вам внедрять байесовские модели в производство? Вы не одиноки. Хотя байесовские модели предлагают мощный инструмент для включения априорных знаний и количественной оценки неопределенности, их внедрение в промышленность было ограничено одним критическим фактором: традиционные методы вывода чрезвычайно медленные, особенно при масштабировании до многомерных пространств. В этом руководстве я покажу вам, как ускорить ваш байесовский вывод до 10 000 раз с помощью многопроцессорного стохастического вариационного вывода (SVI) по сравнению с методами Монте-Карло с цепями Маркова на базе ЦП (MCMC).
Что вы узнаете:
- Различия между методами Монте-Карло и вариационного вывода.
- Как реализовать параллелизм данных на нескольких графических процессорах.
- Пошаговые методы (и код) масштабирования ваших моделей для обработки миллионов или миллиардов наблюдений/параметров.
- Тесты производительности для реализаций ЦП, одного ГП и нескольких ГП
Эта статья продолжает нашу практическую серию по иерархическому байесовскому моделированию, основываясь на нашем предыдущем примере эластичности спроса по цене. Независимо от того, являетесь ли вы специалистом по данным, работающим с большими наборами данных, или академическим исследователем, стремящимся изучить ранее неразрешимые проблемы, эти методы изменят ваш подход к оценке байесовских моделей.
Хотите пропустить теорию и сразу перейти к реализации? Практические примеры кода вы найдете в разделе реализации ниже.
Методы вывода
Напомним нашу базовую спецификацию:
$$log(textrm{Спрос}_{it})= beta_i log(textrm{Цена})_{it} +gamma_{c(i),t} + delta_i + epsilon_{it}$$
Где:
- (textrm{Проданные единицы}_{it} sim textrm{Пуассона}(textrm{Спрос}_{it}, sigma_D) )
- (beta_i sim text{Нормальный}(beta_{c(i)},sigma_i))
- $beta_{c(i)}sim text{Нормальный}(beta_g,sigma_{c(i)})$
- $beta_gsim text{Нормальный}(mu,sigma)$
Мы хотели бы оценить вектор параметров (и их дисперсию) $z = { beta_g, beta_{c(i)}, beta_i, gamma_{c(i),t}, delta_i, text{Demand}_{it} }$, используя данные $x = { text{Units}_{it}, text{Price}_{it}}$. Одним из преимуществ использования байесовских методов по сравнению с частотными подходами является то, что мы можем напрямую моделировать данные о количестве/продажах с распределениями, такими как Пуассон, избегая проблем с нулевыми значениями, которые могут возникнуть при использовании логарифмически преобразованных моделей. Используя байесовский метод, мы указываем априорное распределение (основанное на наших убеждениях) $p(z)$, которое включает наши знания о векторе $z$ до того, как увидим какие-либо данные. Затем, учитывая наблюдаемые данные $x$, мы генерируем вероятность $p(x|z)$, которая сообщает нам, насколько вероятно, что мы наблюдаем данные $x$, учитывая нашу спецификацию $z$. Затем мы применяем правило Байеса $p(z|x) = frac{p(z)p(x|z)}{p(x)}$ для получения апостериорного распределения, которое представляет наши обновленные убеждения относительно параметров с учетом данных. Знаменатель также можно записать как $p(x) = int p(z,x) , dz = int p(z)p(x|z) , dz$. Это сводит наше уравнение к:
$$p(z|x) = frac{p(z)p(x|z)}{int p(z)p(x|z) , dz}$$
Это уравнение требует вычисления апостериорного распределения параметров, обусловленного наблюдаемыми данными $p(z|x)$, которое равно априорному распределению $p(z)$, умноженному на вероятность данных с учетом некоторых параметров $z$. Затем мы делим это произведение на предельное правдоподобие (доказательство), которое является общей вероятностью данных по всем возможным значениям параметров. Сложность вычисления $p(z|x)$ заключается в том, что доказательство требует вычисления многомерного интеграла $p(x) = int p(x|z)p(z)dz$. Многие модели с иерархической структурой или сложными отношениями параметров также не имеют замкнутых решений для интеграла. Более того, вычислительная сложность возрастает экспоненциально с числом параметров, что делает прямые вычисления невыполнимыми для многомерных моделей. Поэтому байесовский вывод на практике проводится путем аппроксимации интеграла.
Теперь мы рассмотрим два самых популярных метода байесовского вывода: Монте-Карло Маркова (MCMC) и Стохастический вариационный вывод (SVI) в следующих разделах. Хотя это самые популярные методы, существуют и другие методы, такие как выборка по важности, фильтры частиц (последовательный Монте-Карло) и распространение ожиданий, но они не будут рассматриваться в этой статье.
Марков-цепь Монте-Карло
Методы MCMC представляют собой класс алгоритмов, которые позволяют нам делать выборки из распределения вероятностей, когда прямая выборка затруднена. В байесовском выводе MCMC позволяет нам делать выборки из апостериорного распределения $p(z|x)$ без явного вычисления интеграла в знаменателе. Основная идея заключается в построении цепи Маркова, стационарное распределение которой равно нашему целевому апостериорному распределению. Математически наше целевое распределение $p(z|x)$ может быть представлено как $pi$, и мы пытаемся построить матрицу перехода $P$ такую, что $pi = pi P$. Как только цепь достигнет своего стационарного распределения (после отбрасывания выборок для сжигания, где цепь может быть нестационарной), каждое последующее состояние цепи будет приблизительно распределено в соответствии с нашим целевым распределением $pi$. Собрав достаточное количество этих выборок, мы можем построить эмпирическое приближение нашего апостериорного распределения, которое становится асимптотически несмещенным по мере увеличения числа выборок.
Методы цепей Маркова — это типы сэмплеров, которые предоставляют различные подходы для построения матрицы перехода $P$. Наиболее фундаментальным является алгоритм Метрополиса-Гастингса (MH), который предлагает новые состояния из распределения предложений и принимает или отклоняет их на основе отношений вероятностей, которые гарантируют сходимость цепи к целевому распределению. Хотя MH является основой методов цепей Маркова, последние достижения в этой области перешли к более сложным сэмплерам, таким как гамильтонов Монте-Карло (HMC), который включает концепции из физики, включая информацию о градиенте для более эффективного исследования пространства параметров. Наконец, сэмплер по умолчанию в последние годы — это сэмплер No U-Turn (NUTS), который улучшает HMC путем автоматической настройки гиперпараметров HMC.
Несмотря на свои желательные теоретические свойства, методы MCMC сталкиваются со значительными ограничениями при масштабировании до больших наборов данных и многомерных пространств параметров. Последовательная природа MCMC создает вычислительное узкое место, поскольку каждый шаг в цепочке зависит от предыдущего состояния, что затрудняет распараллеливание. Кроме того, методы MCMC обычно требуют оценки функции правдоподобия с использованием всего набора данных на каждой итерации. Хотя текущие исследования предлагают методы преодоления этого ограничения, такие как стохастический градиент и мини-пакетирование, они не получили широкого распространения. Эти проблемы масштабирования сделали применение традиционного байесовского вывода сложной задачей в условиях больших данных.
Стохастический вариационный вывод
Второй класс часто используемых методов для байесовского вывода — стохастический вариационный вывод. Вместо выборки из неизвестного апостериорного распределения мы предполагаем, что существует семейство распределений $mathcal{Q}$, которое может аппроксимировать неизвестное апостериорное $p(z|x)$. Это семейство параметризуется вариационными параметрами $phi$ (также известными как направляющая в Pyro/Numpyro), и наша цель — найти член $q_phi(z) in mathcal{Q}$, который наиболее близко напоминает истинный апостериорный. Стандартное предлагаемое распределение использует приближение среднего поля, поскольку предполагает, что все скрытые переменные взаимно независимы. Это предположение подразумевает, что совместное распределение факторизуется в произведение маргинальных распределений, что делает вычисления более податливыми. В качестве примера мы можем использовать диагональное многомерное нормальное распределение в качестве направляющей, а параметры $phi$ будут параметром местоположения и масштаба каждого диагонального элемента. Поскольку все ковариационные члены установлены равными нулю, это семейство распределений имеет взаимно независимые параметры. Это особенно проблематично для данных о продажах, поскольку эффекты перетока широко распространены.
В отличие от MCMC, который использует выборку, SVI формулирует байесовский вывод как задачу оптимизации, минимизируя расхождение Кульбака-Лейблера (KL) между нашим приближением и истинным апостериорным значением: $text{KL}(q_phi(z) || p(z|x))$. Хотя мы не можем легко вычислить полное расхождение, минимизация KL-расхождения эквивалентна максимизации нижней границы доказательств (ELBO) (вывод) стохастически с использованием устоявшихся методов оптимизации.
Исследования в этом направлении, как правило, сосредоточены на двух основных направлениях: улучшение вариационного семейства $mathcal{Q}$ или разработка лучших версий ELBO. Более выразительные семейства, такие как нормализация потоков, могут захватывать сложные апостериорные геометрии, но требуют более высоких вычислительных затрат. ELBO со взвешенным значением выводит более жесткую границу логарифмического маргинального правдоподобия, уменьшая смещение SVI. Поскольку SVI по сути является методом минимизации, он также выигрывает от алгоритмов оптимизации, разработанных для глубокого обучения. Эти улучшения позволяют масштабировать SVI до чрезвычайно больших наборов данных, однако за счет некоторого качества аппроксимации. Кроме того, предположение о среднем поле подразумевает, что апостериорная неопределенность SVI имеет тенденцию недооцениваться. Это означает, что достоверные интервалы слишком узкие и могут некорректно захватывать истинные значения параметров, что мы показываем в части 1 этой серии.
Какой из них использовать
Поскольку целью этой статьи является масштабирование, мы будем использовать SVI для будущих приложений. Как отмечено в Blei et al. (2016), «вариационный вывод подходит для больших наборов данных и сценариев, где мы хотим быстро исследовать много моделей; MCMC подходит для меньших наборов данных и сценариев, где мы с радостью платим большую вычислительную стоимость за более точные образцы». Статьи, применяющие SVI, показали значительное ускорение вывода (до 3 порядков) при применении к многочленным моделям логит, астрофизике и маркетингу больших данных.
Разделение данных
JAX — это библиотека Python для ориентированных на ускоритель вычислений массивов, которая объединяет знакомый API NumPy с ускорением GPU/TPU и автоматической дифференциацией. Под капотом JAX использует как JIT, так и XLA для эффективной компиляции и оптимизации вычислений. Ключевым моментом этой статьи является способность JAX распределять данные по нескольким устройствам (разделение данных), что обеспечивает параллельную обработку путем разделения вычислений по аппаратным ресурсам. В контексте нашей модели это означает, что мы можем разделить наш вектор $X$ по устройствам для ускорения конвергенции SVI. JAX также допускает репликацию, которая дублирует данные по всем устройствам. Это важно для некоторых параметров нашей модели (глобальная эластичность, эластичность категории и фиксированный эффект подкатегории по времени), которые являются информацией, которая потенциально может понадобиться всем устройствам. Для нашего примера с эластичностью цены мы разделим индексы и данные, реплицируя коэффициенты.
Последний момент, который следует отметить, заключается в том, что ведущее измерение сегментированных массивов в JAX должно делиться на количество устройств в системе. Для двумерного массива это означает, что количество строк должно делиться на количество устройств. Поэтому мы должны написать пользовательскую вспомогательную функцию для заполнения массивов, которые мы передаем в нашу функцию спроса, в противном случае мы получим ошибку. Это вычисление также должно быть выполнено вне модели, в противном случае каждая итерация SVI будет повторять заполнение и замедлять вычисление. Поэтому вместо того, чтобы передавать наш DataFrame напрямую в модель, мы предварительно вычислим все требуемые преобразования снаружи и передадим их в модель.
Реализация и оценка
Предыдущую версию модели можно посмотреть в предыдущей статье. В дополнение к нашему DGP из предыдущего примера мы добавляем две функции для создания словаря из нашего DataFrame и для заполнения массивов, чтобы они делились на количество устройств. Затем мы перемещаем все вычисления (вычисление размеров пластин, получение цен на журналы, индексирование) за пределы модели, а затем возвращаем их в модель в виде словаря.
import jax import jax.numpy as jnp def pad_array(arr): num_devices = jax.device_count() остаток = arr.shape[0] % num_devices если остаток == 0: return arr pad_size = num_devices — остаток padding = [(0, pad_size)] + [(0, 0)] * (arr.ndim — 1) # Выберите подходящее значение отступа на основе типа данных pad_value = -1 if arr.dtype in (jnp.int32, jnp.int64) else -1.0 return jnp.pad(arr, padding, constant_values=pad_value) def create_dict(df): # Определите индексы product_idx, unique_product = pd.factorize(df['product']) cat_idx, unique_category = pd.factorize(df['category']) time_cat_idx, unique_time_cat = pd.factorize(df['cat_by_time']) # Преобразуем ряд цен и единиц в массивы jax numpy log_price = jnp.log(df.price.values) result = jnp.array(df.units_sold.values, dtype=jnp.int32) # Генерируем сопоставление product_to_category = jnp.array(pd.DataFrame({'product': product_idx, 'category': cat_idx}).drop_duplicates().category.values, dtype=np.int16) return { 'product_idx': pad_array(product_idx), 'time_cat_idx': pad_array(time_cat_idx), 'log_price': pad_array(log_price), 'product_to_category': product_to_category, 'outcome': result, 'cat_idx': cat_idx, 'n_obs': result.shape[0], 'n_product': unique_product.shape[0], 'n_cat': unique_category.shape[0], 'n_time_cat': unique_time_cat.shape[0], } data_dict = create_dict(df) data_dict {'product_idx': Array([ 0, 0, 0, …, 11986, 11986, -1], dtype=int32), 'time_cat_idx': Array([ 0, 1, 2, …, 1254, 1255, -1], dtype=int32), 'log_price': Array([ 6.629865 , 6.4426994, 6.4426994, …, 5.3833475, 5.3286524, -1. ], dtype=float32), 'product_to_category': Массив([0, 1, 2, …, 8, 8, 7], dtype=int16), 'outcome': Массив([9, 13, 11, …, 447, 389, 491], dtype=int32), 'cat_idx': Массив([0, 0, 0, …, 7, 7, 7]), 'n_obs': 1881959, 'n_product': 11987, 'n_cat': 10, 'n_time_cat': 1570}
После изменения входных данных модели нам также необходимо изменить некоторые компоненты модели. Во-первых, размеры для каждой пластины теперь предварительно вычисляются, и мы можем просто ввести их в создание пластины. Чтобы применить сегментирование и репликацию данных, нам нужно будет добавить сетку (N-мерный массив, который определяет, как данные должны быть разделены) и определить, какие входные данные должны быть сегментированы, а какие — реплицированы. Переменная in_spec определяет, какие входные аргументы должны быть сегментированы/реплицированы по измерению «пакет», определенному в нашей сетке. Затем мы переопределяем функцию calculate_demand, убедившись, что каждый аргумент соответствует правильному порядку in_spec. Мы используем jax.experimental.shard_map.shard_map, чтобы сообщить JAX, что он должен автоматически распараллелить вычисление нашей функции по сегментам, а затем использовать функцию sharded для вычисления спроса, если аргумент модели parallel имеет значение True. Наконец, мы изменяем data_plate так, чтобы принимать только не дополненные индексы, включив ind, поскольку размер исходных данных хранится в переменной n_obs словаря.
from jax.sharding import Mesh from jax.sharding import PartitionSpec as P import jax.experimental.shard_map import numpyro import numpyro.distributions as dist from numpyro.infer.reparam import LocScaleReparam def model(data_dict, result: None, parallel:bool = False): # получить информацию из словаря product_to_category = data_dict['product_to_category'] product_idx = data_dict['product_idx'] log_price = data_dict['log_price'] time_cat_idx = data_dict['time_cat_idx'] # Создать пластины для хранения параметров category_plate = numpyro.plate(«category», data_dict['n_cat']) time_cat_plate = numpyro.plate(«time_cat», data_dict['n_time_cat']) product_plate = numpyro.plate(«product», data_dict['n_product']) data_plate = numpyro.plate(«data», size=data_dict['n_obs']) # ОПРЕДЕЛЕНИЕ ПАРАМЕТРОВ МОДЕЛИ global_a = numpyro.sample(«global_a», dist.Normal(-2, 1), infer={«reparam»: LocScaleReparam()}) с category_plate: category_a = numpyro.sample(«category_a», dist.Normal(global_a, 1), infer={«reparam»: LocScaleReparam()}) с product_plate: product_a = numpyro.sample(«product_a», dist.Normal(category_a[product_to_category], 2), infer={«reparam»: LocScaleReparam()}) product_effect = numpyro.sample(«product_effect», dist.Normal(0, 3), infer={«reparam»: LocScaleReparam()}) с time_cat_plate: time_cat_effects = numpyro.sample(«time_cat_effects», dist.Normal(0, 3), infer={«reparam»: LocScaleReparam()}) # Расчет ожидаемого спроса # Определение информации об устройстве devices = np.array(jax.devices()) num_gpus = len(devices) mesh = Mesh(devices, («batch»,)) # Определение шардинга/репликации ввода и вывода in_spec=( P(), # product_a: replicate P(«batch»), # product_idx: shard P(«batch»), # log_price: shard P(), # time_cat_effects: replicate P(«batch»), # time_cat_idx: shard P(), # product_effect: replicate ) out_spec=P(«batch») # expected_demand: shard def calculate_demand( product_a, product_idx, log_price, time_cat_effects, time_cat_idx, product_effect, ): log_demand = product_a[product_idx]*log_price + time_cat_effects[time_cat_idx] + product_effect[product_idx] expected_demand = jnp.exp(jnp.clip(log_demand, -4, 20)) # обрезать для стабильности и возвести в степень return expected_demand shard_calc = jax.experimental.shard_map.shard_map( calculate_demand, mesh=mesh, in_specs=in_spec, out_specs=out_spec ) calculate_fn = shard_calc если параллельно else calculate_demand demand = calculate_fn( product_a, product_idx, log_price, time_cat_effects, time_cat_idx, product_effect, ) с data_plate как ind: # Примеры наблюдений numpyro.sample( «obs», dist.Poisson(demand[ind]), obs=outcome ) numpyro.render_model( model=model, model_kwargs={«data_dict»: data_dict,»outcome»: data_dict['outcome']}, render_distributions=True, render_params=True, )

Оценка
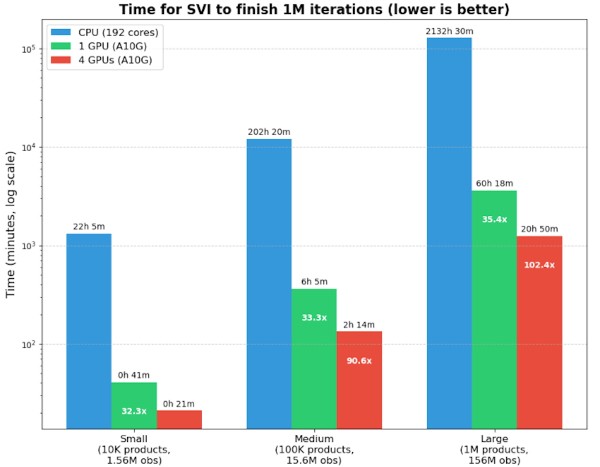
Чтобы получить доступ к распределенным ресурсам GPU, мы запускаем этот блокнот на экземпляре SageMaker Notebook в AWS с использованием экземпляра G5.24xlarge. Этот экземпляр G5 имеет 192 vCPU и 4 GPU NVIDIA A10G. Поскольку NumPyro дает нам удобный индикатор выполнения, мы сравним скорость оптимизации по трем различным размерам моделей: работая либо параллельно на всех ядрах CPU, либо на одном GPU, либо распределенно на всех 4 GPU. Мы оценим ожидаемое время, необходимое для завершения одного миллиона наблюдений по трем размерам наборов данных. Все наборы данных будут иметь 156 периодов с увеличивающимся числом продуктов от 10 тыс., 100 тыс. и 1 млн. Наименьший набор данных будет иметь 1,56 млн наблюдений, а наибольший набор данных будет иметь 156 млн наблюдений. Для оптимизатора мы используем взвешенный ADAM optax с экспоненциально затухающим графиком для скорости обучения. При запуске алгоритма SVI имейте в виду, что Numpyro требуется некоторое время для компиляции всего кода и данных, поэтому возникают некоторые накладные расходы по мере увеличения размера данных и сложности модели.
Вместо оптимизации по стандартному ELBO мы используем потерю RenyiELBO для реализации $alpha$-дивергенции Реньи. В качестве аргумента по умолчанию $alpha=0$ реализует ELBO с весовыми коэффициентами по важности, что дает нам более узкую границу и меньшее смещение. Для руководства мы используем стандартное руководство AutoNormal, которое параметризует диагональное многомерное нормальное распределение для апостериорного распределения. AutoMultivariateNormal и нормализующие потоки (AutoBNAFNormal, AutoIAFNormal) требуют $O(n^2)$ памяти, чего мы не можем сделать на больших моделях. AutoLowRankMultivariateNormal может улучшить апостериорный вывод и использует только $O(kn)$ памяти, где $k$ — гиперпараметр ранга. Однако для этого примера мы используем стандартную формулировку.
100%|██████████| 10000/10000 [00:36<00:00, 277,49ит/с, начальные потери: 131118161920,0000, средн. loss [9501-10000]: 10085247.5700] #пример индикатора выполнения ## SVI import gc from numpyro.infer import SVI, autoguide, init_to_median, RenyiELBO import optax import matplotlib.pyplot as plt numpyro.set_platform('gpu') # Сообщает numpyro/JAX использовать GPU в качестве устройства по умолчанию rng_key = jax.random.PRNGKey(42) guide = autoguide.AutoNormal(model) learning_rate_schedule = optax.exponential_decay( init_value=0.01, transition_steps=1000, decay_rate=0.99, ladder = False, end_value = 1e-5, ) # Определяет оптимизатор optimizer = optax.adamw(learning_rate=learning_rate_schedule) # Код для запуска 4 вычислений GPU gc.collect() jax.clear_caches() svi = SVI(model, guide, optimizer, loss=RenyiELBO(num_particles=4)) svi_result = svi.run(rng_key, 1_000_000, data_dict, data_dict['outcome'], parallel = True) # Код для запуска 1 вычисления GPU gc.collect() jax.clear_caches() svi = SVI(model, guide, optimizer, loss=RenyiELBO(num_particles=4)) svi_result = svi.run(rng_key, 1_000_000, data_dict, data_dict['outcome'], parallel = False) # Код для запуска параллельных вычислений CPU (parallel = False), поскольку все ЦП рассматриваются как одно устройство с jax.default_device(jax.devices('cpu')[0]): gc.collect() jax.clear_caches() svi = SVI(model, guide, optimizer, loss=RenyiELBO(num_particles=4)) svi_result = svi.run(rng_key, 1_000_000, data_dict, data_dict['outcome'], parallel = False)
| Размер набора данных | ЦП (192 ядра) | 1 графический процессор (A10G) | 4 графических процессора (A10G) |
|---|---|---|---|
| Маленький (10 тыс. товаров, 1,56 млн наблюдений, 21,6 тыс. параметров) | ~22:05 | ~0:41 [32.3x] | ~0:21 [63.1x] |
| Средний (100 тыс. товаров, 15,6 млн наблюдений, 201,5 тыс. параметров) | ~202:20 | ~6:05 [33,3x] | ~2:14 [90.6x] |
| Большой (1 млн продуктов, 156 млн наблюдений, 2 млн параметров) | ~2132:30 | ~60:18 [35.4x] | ~20:50 [102.4x] |

В качестве точки отсчета мы также запустили наименьший набор данных с использованием сэмплера NUTS с 3000 отрисовками (1000 приработок), что заняло бы около 20 часов на 192-ядерном ЦП, но не гарантирует сходимости. MCMC также должен увеличить количество отрисовок и приработок по мере усложнения апостериорного пространства, поэтому надлежащие оценки времени для MCMC трудно измерить. Для SVI наши результаты демонстрируют существенное улучшение производительности при переходе с ЦП на ГП, примерно с 32-35-кратным ускорением в зависимости от размера набора данных. Масштабирование с одного ГП до четырех ГП дает еще больший значительный прирост производительности, начиная от 2-кратного ускорения для небольшого набора данных и заканчивая 2,9-кратным ускорением для большого набора данных. Это указывает на то, что накладные расходы на распределение вычислений становятся все более оправданными по мере роста размера проблемы.
Эти результаты показывают, что многопроцессорные конфигурации необходимы для оценки больших иерархических байесовских моделей в разумные сроки. Преимущества производительности становятся еще более выраженными с более продвинутым оборудованием. Например, в моем рабочем приложении переход от конфигурации A10 4-GPU к конфигурации H100 8-GPU увеличил скорость вывода с 5 итераций в секунду до 260 итераций в секунду — ускорение в 52 раза! По сравнению с традиционными подходами MCMC на основе CPU для больших моделей потенциальное ускорение может достигать 10 000 раз, что позволяет ученым решать ранее неразрешимые проблемы.
Примечание по обучению Mini-Batch: я заставил этот код работать с minibatching, но скорость модели на самом деле значительно замедляется по сравнению с загрузкой полного набора данных на GPU. Я предполагаю, что есть некоторые потери при создании индексов для пакетирования, перемещении данных из CPU в GPU, а затем распределении данных и индексов по GPU. Из того, что я видел на практике, minibatching с 1024 на пакет занимает в 2-3 раза больше времени, чем случай с 4 GPU, а batching с 1048576 на пакет занимает в 8 раз больше времени, чем случай с 4 GPU. Поэтому, если набор данных может поместиться в памяти, лучше не включать minibatching .
Заключительные замечания
В этом руководстве показано, как значительно ускорить иерархические байесовские модели, используя комбинацию SVI и многопроцессорной настройки. Этот подход до 102 раз быстрее, чем традиционный SVI на базе CPU при работе с большими наборами данных, содержащими миллионы параметров. В сочетании с ускорением, которое SVI предлагает по сравнению с MCMC, мы можем получить прирост производительности до 10 000 раз. Эти улучшения делают ранее неразрешимые иерархические модели практичными для реальных промышленных приложений.
В этой статье есть несколько ключевых выводов. (1) SVI необходим для масштабирования по сравнению с MCMC за счет точности. (2) Преимущества настройки с несколькими GPU существенно возрастают по мере увеличения объема данных. (3) Реализация кода имеет значение, поскольку только перемещение всех предварительных вычислений за пределы модели позволяет нам достичь этой скорости. Однако, хотя этот подход обеспечивает значительное повышение скорости, несколько ключевых недостатков все еще существуют. Включение мини-пакетирования снижает распределенную производительность, но может быть необходимо на практике для наборов данных, которые слишком велики для размещения в памяти GPU. Эту проблему можно несколько смягчить, используя более продвинутые GPU (A100, H100) с 80 ГБ памяти вместо 24 ГБ, которые предлагает A10G. Эта интеграция мини-пакетирования и распределенных вычислений является многообещающей областью для будущей работы. Во-вторых, предположение о среднем поле в нашем подходе SVI имеет тенденцию недооценивать апостериорную неопределенность по сравнению с полным MCMC, что может повлиять на приложения, где количественная оценка неопределенности имеет решающее значение. Другие руководства могут включать более сложную апостериорную, но это достигается за счет масштабирования памяти (обычно экспоненциального) и не будет осуществимо для больших наборов данных. Как только я найду лучший способ исправления апостериорной неопределенности посредством постобработки, я также напишу статью об этом…
Применение: Методы, продемонстрированные в этой статье, открывают двери для многочисленных приложений, которые ранее были вычислительно невыгодными. Маркетинговые команды теперь могут создавать детализированные модели маркетингового микса, которые фиксируют различия между регионами и профилями клиентов и предоставляют локализованные оценки эффективности канала. Финансовые учреждения могут внедрять крупномасштабные расчеты стоимости под риском, которые моделируют сложные зависимости между тысячами ценных бумаг, одновременно фиксируя изменения в поведении рынка, специфичные для сегмента. Технологические компании могут разрабатывать гибридные системы рекомендаций, которые интегрируют как совместную, так и основанную на контенте фильтрацию с байесовской неопределенностью, что позволяет улучшить компромиссы между разведкой и эксплуатацией. В макроэкономике исследователи могут оценивать модели полностью гетерогенных агентов (HANK), которые измеряют, как денежно-кредитная и фискальная политика дифференцированно влияет на различных экономических субъектов, вместо того, чтобы просто использовать репрезентативных агентов.
Если у вас есть возможность применить эту концепцию в своей работе, я бы с удовольствием об этом узнал. Не стесняйтесь обращаться ко мне с вопросами, идеями или историями по электронной почте или LinkedIn. Если у вас есть какие-либо отзывы об этой статье или вы хотели бы запросить другую тему в области причинно-следственной связи/машинного обучения, пожалуйста, также не стесняйтесь обращаться. Спасибо за чтение!
Примечание : Все изображения, использованные в этой статье, созданы автором.
Источник: towardsdatascience.com