
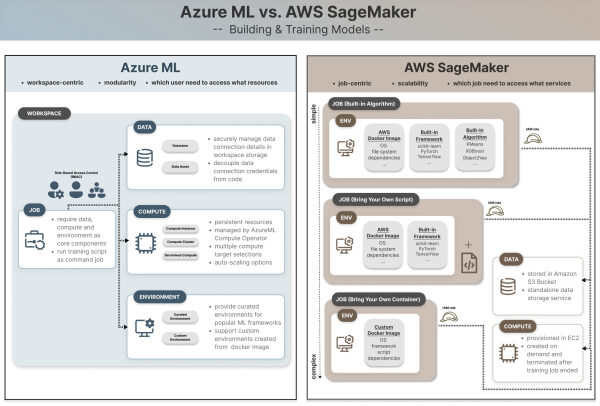
Сравните структуру проекта машинного обучения, управление разрешениями и хранение данных в Azure и AWS.
Делиться

Microsoft Azure и Amazon Web Services (AWS) — две крупнейшие в мире платформы облачных вычислений, предоставляющие ресурсы баз данных, сетей и вычислительных ресурсов в глобальном масштабе. Вместе они занимают около 50% мирового рынка корпоративных облачных инфраструктурных сервисов — AWS на 30%, а Azure на 20%. Azure ML и AWS SageMaker — это сервисы машинного обучения, которые позволяют специалистам по обработке данных и инженерам машинного обучения разрабатывать и управлять всем жизненным циклом машинного обучения, от предварительной обработки данных и проектирования признаков до обучения моделей, развертывания и мониторинга. Вы можете создавать и управлять этими сервисами машинного обучения в AWS и Azure через консольные интерфейсы, облачный CLI или комплекты разработки программного обеспечения (SDK) на предпочитаемом вами языке программирования — подход, описанный в этой статье.
Вакансии по обучению работе с Azure ML и AWS SageMaker
Несмотря на схожие высокоуровневые функции, Azure ML и AWS SageMaker имеют принципиальные различия, определяющие, какая платформа лучше всего подходит вам, вашей команде или вашей компании. Во-первых, следует учитывать экосистему существующих хранилищ данных, вычислительных ресурсов и служб мониторинга. Например, если данные вашей компании в основном хранятся в хранилище AWS S3, то SageMaker может стать более естественным выбором для разработки ваших сервисов машинного обучения, поскольку он снижает накладные расходы на подключение и передачу данных между различными облачными провайдерами. Однако это не означает, что другие факторы не стоит учитывать, и мы подробно рассмотрим, чем Azure ML отличается от AWS SageMaker в типичном сценарии машинного обучения — обучении и построении моделей в масштабе с использованием заданий.
Хотя блокноты Jupyter ценны для экспериментов и исследований в интерактивном процессе разработки на одном устройстве, они не предназначены для внедрения в производство или распространения. На этом этапе задачи обучения (и другие задачи машинного обучения) становятся важными в рабочем процессе машинного обучения, поскольку их выполнение может занимать больше времени и обрабатывать больший объем данных. Это требует настройки данных, кода, вычислительных экземпляров и среды выполнения для обеспечения согласованных результатов, когда задача больше не выполняется на одной локальной машине. Представьте себе разницу между разработкой рецепта ужина (блокнот Jupyter) и наймом команды кейтеринга для приготовления блюд для 500 клиентов (задача машинного обучения). В первом случае все члены команды кейтеринга должны иметь доступ к одним и тем же ингредиентам, рецепту и инструментам, следуя одной и той же процедуре приготовления.
Теперь, когда мы понимаем важность обучающих задач, давайте вкратце рассмотрим, как они определяются в Azure ML и SageMaker.
Определить задачу обучения Azure ML
from azure.ai.ml import command job = command( code=… command=… environment=… compute=… ) ml_client.jobs.create_or_update(job)
Создать обучающий инструмент оценки стоимости работ в SageMaker
from sagemaker.estimator import Estimator estimator = Estimator( image_uri=… role=… instance_type=… ) estimator.fit(training_data_s3_location)
Мы разделим сравнение на следующие параметры:
- Управление проектами и получением разрешений
- хранение данных
- Вычислить
- Среда
В первой части мы начнем со сравнения высокоуровневой настройки проекта и управления правами доступа , а затем поговорим о хранении и доступе к данным, необходимым для обучения модели. Во второй части будут рассмотрены различные варианты вычислительных ресурсов на обеих облачных платформах, а также способы создания и управления средами выполнения для задач обучения.
Управление проектами и получением разрешений
Начнём с понимания типичного рабочего процесса машинного обучения в команде среднего или большого размера, состоящей из специалистов по анализу данных, инженеров данных и инженеров машинного обучения. Каждый член команды может специализироваться на определённой роли и обязанностях и быть назначен на один или несколько проектов. Например, инженер данных отвечает за извлечение данных из источника и их хранение в централизованном месте для обработки специалистами по анализу данных. Ему не нужно запускать вычислительные экземпляры для выполнения задач обучения. В этом случае у него может быть доступ на чтение и запись к месту хранения данных, но ему не обязательно нужен доступ для создания экземпляров GPU для ресурсоёмких задач. В зависимости от конфиденциальности данных и роли в проекте машинного обучения, членам команды необходимы разные уровни доступа к данным и базовой облачной инфраструктуре. Мы рассмотрим, как две облачные платформы структурируют свои ресурсы и сервисы, чтобы сбалансировать требования к командной работе и разделению ответственности.
Azure ML

Управление проектами в Azure ML ориентировано на рабочие пространства . Начинается всё с создания рабочего пространства (в рамках вашей подписки Azure и группы ресурсов) для хранения соответствующих ресурсов и активов, которое затем становится доступным для всей проектной команды для совместной работы.
Доступ к ресурсам и управление ими предоставляются на уровне пользователя в зависимости от его роли — то есть, используется управление доступом на основе ролей (RBAC). К общим ролям в Azure относятся владелец, участник и читатель. Специализированные роли для машинного обучения включают AzureML Data Scientist и AzureML Compute Operator, которые отвечают за создание и управление вычислительными экземплярами, поскольку они, как правило, являются самым затратным элементом в проекте машинного обучения. Цель создания рабочей области Azure ML — создать изолированную среду для хранения данных, вычислительных ресурсов, моделей и других ресурсов, чтобы только пользователи в рабочей области имели соответствующий доступ к чтению или редактированию данных, использованию существующих или созданию новых вычислительных экземпляров в соответствии со своими обязанностями.
В приведенном ниже фрагменте кода мы подключаемся к рабочей области Azure ML через MLClient, передавая идентификатор подписки рабочей области, группу ресурсов и учетные данные по умолчанию — Azure следует иерархической структуре: Подписка > Группа ресурсов > Рабочая область.
При создании рабочей области автоматически создаются связанные с ней службы, такие как учетная запись хранилища Azure (хранит метаданные и артефакты, а также может хранить обучающие данные) и хранилище ключей Azure (хранит секреты, такие как имена пользователей, пароли и учетные данные).
from azure.ai.ml import MLClient from azure.identity import DefaultAzureCredential subscription_id = '
Когда разработчики запускают код во время интерактивной сессии разработки, подключение к рабочей области аутентифицируется с помощью личных учетных данных разработчика. Они смогут создать задание обучения, используя команду ml_client.jobs.create_or_update(job), как показано ниже. Для отсоединения личных учетных данных в производственной среде рекомендуется использовать учетную запись субъекта службы для аутентификации в автоматизированных конвейерах или запланированных заданиях. Дополнительную информацию можно найти в этой статье «Аутентификация в рабочей области с помощью субъекта службы».
# Определяем задачу обучения Azure ML из azure.ai.ml import command job = command( code=… command=… environment=… compute=… ) ml_client.jobs.create_or_update(job)
AWS SageMaker

Роли и разрешения в SageMaker разработаны на основе совершенно иного принципа, в основном с использованием «ролей» в сервисе AWS Identity Access Management (IAM). Хотя IAM позволяет создавать доступ на уровне пользователя (или учетной записи), аналогично Azure, AWS рекомендует предоставлять разрешения на уровне задания на протяжении всего жизненного цикла машинного обучения. Таким образом, ваши личные разрешения AWS не имеют значения во время выполнения, и SageMaker принимает на себя роль (т.е. роль выполнения SageMaker) для доступа к соответствующим сервисам AWS, таким как корзина S3, конвейер обучения SageMaker, вычислительные экземпляры для выполнения задания.
Например, вот краткий обзор настройки оценщика с ролью выполнения SageMaker для запуска задания обучения.
import sagemaker from sagemaker.estimator import Estimator # Получаем роль выполнения SageMaker role = sagemaker.get_execution_role() # Определяем оценщик estimator = Estimator( image_uri=image_uri, role=role, # принимаем роль выполнения SageMaker во время выполнения instance_type=»ml.m5.xlarge», instance_count=1, ) # Начинаем обучение estimator.fit(«s3://my-training-bucket/train/»)
Это означает, что мы можем настроить достаточную детализацию, чтобы предоставлять ролям разрешения на запуск только обучающих заданий в среде разработки, но не затрагивать производственную среду. Например, если роли предоставляется доступ к S3-хранилищу, содержащему тестовые данные, и блокируется доступ к хранилищу, содержащему производственные данные, то обучающее задание, выполняющееся с использованием этой роли, не сможет случайно перезаписать производственные данные.
Управление разрешениями в AWS — это сложная область сама по себе, и я не буду делать вид, что могу полностью объяснить эту тему. Я рекомендую прочитать эту статью, чтобы узнать больше о лучших практиках из официальной документации AWS: « Управление разрешениями ».
Что это означает на практике?
- Azure ML : Управление доступом на основе ролей (RBAC) в Azure подходит для компаний или команд, которые управляют тем, какому пользователю необходим доступ к каким ресурсам . Оно более интуитивно понятно и полезно для централизованного управления доступом пользователей.
- AWS SageMaker AI : AWS подходит для систем, которым важно, какой задаче нужен доступ к каким сервисам . Разделение прав доступа отдельных пользователей и выполнения задач обеспечивает лучшую автоматизацию и внедрение методов MLOps. AWS подходит для больших команд специалистов по анализу данных с детальным определением задач и конвейеров, а также изолированными средами.
Ссылка
- https://docs.aws.amazon.com/whitepapers/latest/sagemaker-studio-admin-best-practices/permissions-management.html
- https://github.com/MicrosoftDocs/azure-ai-docs/blob/main/articles/machine-learning/how-to-assign-roles.md
Хранение данных
Возможно, у вас возник вопрос — можно ли хранить данные в рабочей директории? По крайней мере, меня это давно волнует, и я считаю, что ответ по-прежнему положительный, если вы экспериментируете или создаете прототипы, используя простой скрипт или блокнот в интерактивной среде разработки. Но место хранения данных важно учитывать в контексте создания заданий машинного обучения.
Поскольку код выполняется в облачной среде или в контейнере Docker, отдельном от локального каталога, доступ к локально хранящимся данным при выполнении конвейеров и заданий в SageMaker или Azure ML невозможен. Для этого требуются централизованные, управляемые службы хранения данных. В Azure это решается с помощью учетной записи хранения в рабочей области, которая поддерживает хранилища данных и информационные ресурсы.
Хранилища данных содержат информацию о подключении, тогда как активы данных представляют собой версионированные снимки данных, используемые для обучения или вывода результатов. AWS, с другой стороны, в значительной степени полагается на корзины S3 в качестве централизованных мест хранения, которые обеспечивают безопасный, надежный доступ к данным в разных регионах, и пользователи могут получать доступ к данным через уникальный URI-путь.
Azure ML

В рабочих областях Azure ML рассматривает данные как подключенные ресурсы и активы, при этом при создании каждой рабочей области автоматически создается одна учетная запись хранения и четыре встроенных хранилища данных для хранения файлов (в Azure File Share) и наборов данных (в Azure Blob Storage).

Поскольку хранилища данных надежно хранят информацию о подключении к данным и автоматически обрабатывают учетные данные/идентификацию, это отделяет местоположение данных и права доступа от кода, так что код остается неизменным, даже если базовое подключение к данным изменяется. Доступ к хранилищам данных осуществляется через их уникальный URI. Вот пример создания объекта Input типа uri_file с передачей пути к хранилищу данных.
# Создание обучающих данных с использованием Datastore training_data=Input( type=»uri_file», path=»
Затем эти данные можно использовать в качестве обучающих данных для задачи классификации AutoML.
classification_job = automl.classification( compute='aml-cluster', training_data=training_data, target_column_name='Survived', primary_metric='accuracy', )
Доступ к данным в задании машинного обучения с помощью Data Asset — это еще один вариант, особенно когда важно отслеживать несколько версий данных, чтобы специалисты по анализу данных могли определить правильные снимки данных, используемые для построения модели или экспериментов. Вот пример кода для создания объекта Input с типом AssetTypes.URI_FILE, передав путь к данным в Data Asset «azureml:my_train_data:1» (который включает имя данных в Data Asset + номер версии) и используя режим InputOutputModes.RO_MOUNT для доступа только для чтения. Дополнительную информацию можно найти в документации «Доступ к данным в задании».
# Создание обучающих данных с использованием Data Asset training_data = Input( type=AssetTypes.URI_FILE, path=»azureml:my_train_data:1″, mode=InputOutputModes.RO_MOUNT )
AWS SageMaker

AWS SageMaker тесно интегрирован с Amazon S3 (Simple Storage Service) для рабочих процессов машинного обучения, поэтому задания обучения SageMaker, конечные точки вывода и конвейеры могут обрабатывать входные данные из хранилищ S3 и записывать выходные данные обратно в них. Возможно, вы обнаружите, что для создания среды управляемого задания SageMaker (которая будет обсуждаться во второй части) в качестве ключевого параметра требуется указать местоположение хранилища S3; в противном случае будет создано хранилище по умолчанию, если оно не указано.
В отличие от подхода Azure ML, ориентированного на рабочее пространство, AWS S3 — это автономная служба хранения данных, предоставляющая масштабируемое, надежное и безопасное облачное хранилище, которое может использоваться совместно с другими сервисами и учетными записями AWS. Это обеспечивает большую гибкость в управлении разрешениями на уровне отдельных папок, но в то же время требует явного предоставления роли выполнения SageMaker доступа к корзине S3.
В этом фрагменте кода мы используем estimator.fit(train_data_uri) для обучения модели на обучающих данных, передавая непосредственно URI S3, затем генерируем выходную модель и сохраняем ее в указанном месте в S3-корзине. Больше примеров можно найти в их документации: «Примеры использования Amazon S3 с помощью SDK для Python (Boto3)».
import sagemaker # Определяем пути к S3 train_data_uri = «
Что это означает на практике?
- Azure ML: использует Datastore для управления подключениями к данным, который обрабатывает информацию об учетных данных/идентификаторах в фоновом режиме. Таким образом, этот подход отделяет местоположение данных и разрешения доступа от кода, позволяя коду оставаться неизменным при изменении базового подключения.
- AWS SageMaker: использование S3-хранилищ в качестве основного сервиса хранения данных для управления входными и выходными данными заданий SageMaker через их URI-пути. Такой подход требует явного управления разрешениями для предоставления роли выполнения SageMaker доступа к необходимому S3-хранилищу.
Ссылка
- https://learn.microsoft.com/en-us/azure/machine-learning/tutorial-explore-data?view=azureml-api-2
- https://learn.microsoft.com/en-us/azure/machine-learning/how-to-read-write-data-v2?view=azureml-api-2&tabs=python
- https://docs.aws.amazon.com/code-library/latest/ug/python_3_s3_code_examples.html
Главный вывод
Сравните Azure ML и AWS SageMaker для масштабируемого обучения моделей, уделяя особое внимание настройке проекта, управлению разрешениями и моделям хранения данных, чтобы команды могли лучше согласовать выбор платформы со своей существующей облачной экосистемой и предпочтительными рабочими процессами MLOps.
В первой части мы сравним высокоуровневую настройку проекта и управление правами доступа, а также хранение и доступ к данным, необходимым для обучения модели. Во второй части будут рассмотрены различные варианты вычислительных ресурсов на обеих облачных платформах, а также создание и управление средами выполнения для задач обучения.
Дополнительные ресурсы
7 советов, как обеспечить перспективность проектов машинного обучения.
Источник: towardsdatascience.com
. 7")




















