
Сравните вычислительные мощности, цены и среду для масштабируемых задач машинного обучения.
Делиться

В первой части этой серии мы рассмотрели, как Azure и AWS используют принципиально разные подходы к управлению проектами в области машинного обучения и хранению данных.
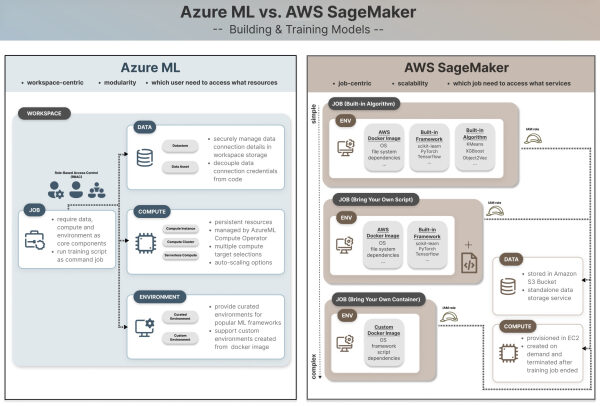
Azure ML использует структуру , ориентированную на рабочие пространства , с управлением доступом на уровне пользователей на основе ролей (RBAC), где разрешения предоставляются отдельным лицам в зависимости от их обязанностей. В отличие от этого, AWS SageMaker использует архитектуру, ориентированную на задания , которая отделяет разрешения пользователей от выполнения заданий, предоставляя доступ на уровне заданий через роли IAM. Для хранения данных Azure ML использует хранилища данных и ресурсы данных в рабочих пространствах для управления подключениями и учетными данными в фоновом режиме, в то время как AWS SageMaker напрямую интегрируется с корзинами S3, требуя явного предоставления разрешений ролям выполнения SageMaker для доступа к данным.
Подробнее читайте в этой статье:
AWS против Azure: подробный анализ обучения моделей — Часть 1
Разобравшись с тем, как эти платформы обрабатывают настройку проекта и доступ к данным, во второй части мы рассмотрим вычислительные ресурсы и среды выполнения , которые обеспечивают работу задач обучения модели.
Вычислить
Вычислительные ресурсы — это виртуальные машины, на которых выполняется ваша модель и код. Наряду с сетью и хранилищем, это один из фундаментальных компонентов облачных вычислений. Вычислительные ресурсы обычно составляют наибольшую часть затрат в проекте машинного обучения, поскольку обучение моделей — особенно больших моделей ИИ — требует длительного времени обучения и часто специализированных вычислительных экземпляров (например, экземпляров с графическими процессорами) с более высокой стоимостью. Поэтому Azure ML разрабатывает специальную роль оператора вычислительных ресурсов AzureML (подробности см. в Части 1) для управления вычислительными ресурсами.
Azure и AWS предлагают различные типы экземпляров, отличающиеся количеством процессоров/графических процессоров, объемом памяти, дисковым пространством и типом, каждый из которых предназначен для определенных целей. Обе платформы используют модель ценообразования «оплата по мере использования», взимая плату только за активное вычислительное время.
Виртуальные машины Azure называются в алфавитном порядке; например, виртуальные машины семейства D предназначены для рабочих нагрузок общего назначения и соответствуют требованиям большинства сред разработки и производства. Вычислительные экземпляры AWS также сгруппированы в семейства в зависимости от их назначения; например, семейство m5 включает экземпляры общего назначения для разработки SageMaker ML. В таблице ниже сравниваются вычислительные экземпляры, предлагаемые Azure и AWS, в зависимости от их назначения, почасовой стоимости и типичных сценариев использования. (Обратите внимание, что структура ценообразования различается в зависимости от региона и тарифного плана, поэтому я рекомендую проверить их официальные веб-сайты.)

Теперь, когда мы сравнили цены на вычислительные ресурсы в AWS и Azure, давайте рассмотрим, чем отличаются эти две платформы в плане интеграции вычислительных ресурсов в системы машинного обучения.
Azure ML

Вычислительные ресурсы — это постоянно доступные ресурсы в рабочей области Azure ML, обычно создаваемые один раз оператором AzureML Compute Operator и повторно используемые командой специалистов по анализу данных. Поскольку вычислительные ресурсы являются дорогостоящими, такая структура позволяет централизованно управлять ими с помощью роли, обладающей опытом работы с облачной инфраструктурой, в то время как специалисты по анализу данных и инженеры могут сосредоточиться на разработке.
Azure предлагает широкий спектр вариантов целевых вычислительных ресурсов, предназначенных для разработки и развертывания машинного обучения, в зависимости от масштаба рабочей нагрузки. Экземпляр вычислительной системы — это одноузловая машина, подходящая для интерактивной разработки и тестирования в среде Jupyter Notebook. Вычислительный кластер — это другой тип целевой вычислительной системы, который запускает многоузловые кластерные машины. Он может масштабироваться для параллельной обработки в зависимости от потребности рабочей нагрузки и поддерживает автоматическое масштабирование путем настройки параметров min_instances и max_instances. Кроме того, существуют бессерверные вычисления, кластеры Kubernetes и контейнеры, подходящие для различных целей. Ниже представлено полезное визуальное резюме, которое поможет вам принять решение в зависимости от вашего варианта использования.
”](/wp-content/uploads/2026/02/8ebee2f596ea68f1d01324a337b8fc06.jpg "Изображение взято из видео «[Изучение и настройка рабочей области Azure Machine Learning DP-100](https://www.youtube.com/watch?v=_f5dlIvI5LQ)»")
Для создания управляемого вычислительного объекта Azure ML мы создаем объект AmlCompute, используя приведенный ниже код:
- Для кластера вычислительных ресурсов используйте «amlcompute». В качестве альтернативы используйте «computeinstance» для интерактивной разработки на одном узле и «kubernetes» для кластеров AKS.
- имя: укажите имя целевого вычислительного объекта.
- размер: укажите размер экземпляра.
- min_instances и max_instances (необязательно): задают диапазон экземпляров, которым разрешено работать одновременно.
- idle_time_before_scale_down (необязательно): автоматически отключает вычислительный кластер при простое, чтобы избежать лишних затрат.
# Создание вычислительного кластера cpu_cluster = AmlCompute( name=»cpu-cluster», type=»amlcompute», size=»Standard_DS3_v2″, min_instances=0, max_instances=4, idle_time_before_scale_down=120 ) # Создание или обновление вычислительного кластера ml_client.compute.begin_create_or_update(cpu_cluster)
После создания вычислительного ресурса любой пользователь в общей рабочей области может использовать его, просто указав его имя в задании машинного обучения, что делает его легкодоступным для совместной работы команды.
# Использовать постоянно доступный вычислительный кластер «cpu-cluster» в задании job = command( code='./src', command='python code.py', compute='cpu-cluster', display_name='train-custom-env', experiment_name='training' )
AWS SageMaker AI

Вычислительные ресурсы управляются отдельным сервисом AWS — EC2 (Elastic Compute Cloud). При использовании этих вычислительных ресурсов в SageMaker разработчикам необходимо явно настраивать тип экземпляра для каждой задачи, после чего вычислительные экземпляры создаются по запросу и завершаются по окончании задачи. Такой подход предоставляет разработчикам большую гибкость в выборе вычислительных ресурсов в зависимости от задачи, но требует больше знаний в области инфраструктуры для выбора и управления соответствующими вычислительными ресурсами. Например, доступные типы экземпляров различаются в зависимости от типа задачи. ml.t3.medium и ml.t3.large обычно используются для работы с блокнотами SageMaker в интерактивных средах разработки, но они недоступны для задач обучения, которые требуют более мощных типов экземпляров из семейств m5, c5, p3 или g4dn.
Как показано в приведенном ниже фрагменте кода, AWS SageMaker указывает вычислительный экземпляр и количество одновременно работающих экземпляров в качестве параметров задания. Во время выполнения задания создается вычислительный экземпляр типа ml.m5.xlarge, и плата взимается в зависимости от времени выполнения задания.
estimator = Estimator( image_uri=image_uri, role=role, instance_type=»ml.m5.xlarge», instance_count=1 )
В SageMaker задания по умолчанию запускают экземпляры по запросу. Оплата производится посекундно, и они обеспечивают гарантированную мощность для выполнения заданий, критичных ко времени. Для заданий, которые могут выдерживать прерывания и более высокую задержку, более экономичным вариантом является использование свободных вычислительных ресурсов на основе спотовых экземпляров. Недостатком является дополнительный период ожидания, когда нет доступных спотовых экземпляров. Мы используем приведенный ниже фрагмент кода для реализации опции спотовых экземпляров для задания обучения.
- use_spot_instances: установите значение True, чтобы использовать спотовые экземпляры, в противном случае по умолчанию используется экземпляры по запросу.
- max_wait: максимальное время, в течение которого вы готовы ждать появления доступных спотовых экземпляров (время ожидания не оплачивается).
max_run: максимально допустимое время обучения для данной задачи. - checkpoint_s3_uri: URI-путь к S3-хранилищу для сохранения контрольных точек модели, позволяющий безопасно перезапустить обучение после ожидания.
estimator = Estimator( image_uri=image_uri, role=role, instance_type=»ml.m5.xlarge», instance_count=1, use_spot_instances=True, max_run=3600, max_wait=7200, checkpoint_s3_uri=»
Что это означает на практике?
- Azure ML : подход Azure к постоянным вычислительным ресурсам позволяет централизованно управлять ими и совместно использовать их несколькими разработчиками, что дает возможность специалистам по обработке данных сосредоточиться на разработке моделей, а не на управлении инфраструктурой.
- AWS SageMaker AI : SageMaker требует от разработчиков явного определения типа вычислительного экземпляра для каждой задачи, что обеспечивает большую гибкость, но также требует более глубоких знаний инфраструктуры, включая типы экземпляров, стоимость и ограничения доступности.
Ссылка
- https://aws.amazon.com/sagemaker/ai/pricing/
- https://learn.microsoft.com/en-us/azure/machine-learning/concept-compute-target?view=azureml-api-2
- https://www.youtube.com/watch?v=_f5dlIvI5LQ
Среда
Среда определяет, где выполняется код или задача, включая программное обеспечение, операционную систему, пакеты программ, образ Docker и переменные среды. В то время как вычислительные ресурсы отвечают за базовую инфраструктуру и выбор оборудования, настройка среды имеет решающее значение для обеспечения согласованного и воспроизводимого поведения в средах разработки и производства, предотвращения конфликтов пакетов и проблем с зависимостями при выполнении одного и того же кода в различных средах выполнения разными разработчиками. Azure ML и SageMaker поддерживают использование собственных настроенных сред, а также настройку пользовательских сред.
Azure ML
Подобно данным и вычислительным ресурсам, среда рассматривается как тип ресурса и актива в рабочей области Azure ML. Azure ML предлагает полный список специально подобранных сред для популярных фреймворков Python (например, PyTorch, Tensorflow, scikit-learn), предназначенных для работы на ЦП или ГП/CUDA.
Приведённый ниже фрагмент кода помогает получить список всех отобранных сред в Azure ML. Как правило, они используют соглашение об именовании, включающее название фреймворка, версию, операционную систему, версию Python и целевую вычислительную среду (CPU/GPU). Например, AzureML-sklearn-1.0-ubuntu20.04-py38-cpu указывает на версию scikit-learn 1.0, работающую на Ubuntu 20.04 с Python 3.8 для вычислений на CPU.
envs = ml_client.environments.list() for env in envs: print(env.name) # >>> Среды, отобранные Azure ML «»» AzureML-AI-Studio-Development AzureML-ACPT-pytorch-1.13-py38-cuda11.7-gpu AzureML-ACPT-pytorch-1.12-py38-cuda11.6-gpu AzureML-ACPT-pytorch-1.12-py39-cuda11.6-gpu AzureML-ACPT-pytorch-1.11-py38-cuda11.5-gpu AzureML-ACPT-pytorch-1.11-py38-cuda11.3-gpu AzureML-responsibleai-0.21-ubuntu20.04-py38-cpu AzureML-responsibleai-0.20-ubuntu20.04-py38-cpu AzureML-tensorflow-2.5-ubuntu20.04-py38-cuda11-gpu AzureML-tensorflow-2.6-ubuntu20.04-py38-cuda11-gpu AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu AzureML-sklearn-1.0-ubuntu20.04-py38-cpu AzureML-pytorch-1.10-ubuntu18.04-py38-cuda11-gpu AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu AzureML-pytorch-1.8-ubuntu18.04-py37-cuda11-gpu AzureML-sklearn-0.24-ubuntu18.04-py37-cpu AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu AzureML-pytorch-1.7-ubuntu18.04-py37-cuda11-gpu AzureML-tensorflow-2.4-ubuntu18.04-py37-cuda11-gpu AzureML-Triton AzureML-Designer-Score AzureML-VowpalWabbit-8.8.0 AzureML-PyTorch-1.3-CPU «»»
Для запуска задачи обучения в специально подготовленной среде мы создаем объект среды, указывая его имя и версию, а затем передаем его в качестве параметра задачи.
# Получение подготовленной среды environment = ml_client.environments.get(«AzureML-sklearn-1.0-ubuntu20.04-py38-cpu», version=44) # Использование подготовленной среды в задании job = command( code=».», command=»python train.py», environment=environment, compute=»cpu-cluster» ) ml_client.jobs.create_or_update(job)
В качестве альтернативы, вы можете создать пользовательскую среду из образа Docker, зарегистрированного в Docker Hob, используя приведенный ниже фрагмент кода.
# Получение подготовленной среды environment = ml_client.environments.get(«AzureML-sklearn-1.0-ubuntu20.04-py38-cpu», version=44) # Использование подготовленной среды в задании job = command( code=».», command=»python train.py», environment=environment, compute=»cpu-cluster» ) ml_client.jobs.create_or_update(job)
AWS SageMaker AI
Конфигурация среды SageMaker тесно связана с определениями заданий, предлагая три уровня настройки для определения операционной системы, фреймворков и пакетов, необходимых для выполнения задания. Это встроенный алгоритм, использование собственного скрипта (режим скрипта) и использование собственного контейнера (BYOC), от самого простого, но жестко регламентированного варианта до самого сложного, но настраиваемого.
Встроенные алгоритмы

Это вариант, требующий наименьших усилий от разработчиков для обучения и развертывания моделей машинного обучения в масштабе AWS SageMaker, а Azure в настоящее время, по состоянию на февраль 2026 года, не предлагает эквивалентного встроенного алгоритмического подхода с использованием Python SDK.
SageMaker инкапсулирует алгоритм машинного обучения, а также зависимости от библиотеки Python и фреймворка в объект оценщика. Например, здесь мы создаем экземпляр оценщика KMeans, указывая специфический для алгоритма гиперпараметр k и передавая обучающие данные для подгонки модели. Затем задача обучения запустит вычислительный экземпляр ml.m5.large, и обученная модель будет сохранена в месте вывода.
Принесите свой собственный сценарий

Подход с использованием собственного скрипта (также известный как режим скрипта или использование собственной модели) позволяет разработчикам использовать предварительно созданные контейнеры SageMaker для популярных фреймворков Python для машинного обучения, таких как scikit-learn, PyTorch и Tensorflow. Он обеспечивает гибкость настройки задачи обучения с помощью собственного скрипта без необходимости управления средой выполнения задачи, что делает его наиболее популярным выбором при использовании специализированных алгоритмов, не включенных во встроенные параметры SageMaker.
В приведенном ниже примере мы создаем экземпляр оценщика, используя фреймворк scikit-learn, предоставляя пользовательский скрипт обучения train.py, гиперпараметры модели, а также версию фреймворка и версию Python.
from sagemaker.sklearn import SKLearn sk_estimator = SKLearn( entry_point=»train.py», role=role, instance_count=1, instance_type=»ml.m5.large», py_version=»py3″, framework_version=»1.2-1″, script_mode=True, hyperparameters={«estimators»: 20}, ) # Обучение оценщика sk_estimator.fit({«train»: training_data})
Принесите свою собственную тару.
Это подход с наивысшим уровнем кастомизации, позволяющий разработчикам создавать собственную среду с помощью образа Docker. Он подходит для сценариев, использующих неподдерживаемые фреймворки Python, специализированные пакеты или другие языки программирования (например, R, Java и т. д.). Рабочий процесс включает в себя создание образа Docker, содержащего все необходимые зависимости пакетов и скрипты для обучения модели, а затем его загрузку в Elastic Container Registry (ECR), сервис регистрации контейнеров AWS, аналог Docker Hub.
В приведенном ниже коде мы указываем пользовательский URI образа Docker в качестве параметра для создания оценщика и обучения оценщика на обучающих данных.
from sagemaker.estimator import Estimator image_uri = «
Что это означает на практике?
- Azure ML : обеспечивает поддержку запуска обучающих заданий с использованием обширной коллекции тщательно подобранных сред, охватывающих популярные фреймворки, такие как PyTorch, TensorFlow и scikit-learn, а также предлагает возможность создания и настройки пользовательских сред из образов Docker для более специализированных случаев использования. Однако важно отметить, что Azure ML в настоящее время не предлагает встроенный алгоритмический подход, который инкапсулирует и упаковывает популярные алгоритмы машинного обучения непосредственно в среду, как это делает SageMaker.
- AWS SageMaker AI : SageMaker известен своими тремя уровнями настройки — встроенный алгоритм, использование собственного скрипта и использование собственного контейнера — которые охватывают широкий спектр требований разработчиков. Встроенный алгоритм и использование собственного скрипта используют управляемые среды AWS и тесно интегрируются с алгоритмами или фреймворками машинного обучения. Они предлагают простоту, но менее подходят для узкоспециализированных процессов обучения моделей.
В итоге
Исходя из приведенного выше сравнения вычислительных ресурсов и среды, а также из того, что мы обсуждали в статье «AWS против Azure: подробный анализ обучения моделей — Часть 1 (Настройка проекта и хранение данных)», мы могли бы понять, что эти две платформы используют разные принципы проектирования для построения своих экосистем машинного обучения.
Azure ML использует более модульную архитектуру , где данные, вычисления и среда рассматриваются как независимые ресурсы и активы в рамках рабочей области Azure ML. Поскольку их можно настраивать и управлять ими отдельно, такой подход более удобен для начинающих, особенно для пользователей без обширных знаний в области облачных вычислений или управления разрешениями. Например, специалист по анализу данных может создать задание на обучение, подключив существующий вычислительный ресурс в рабочей области, без необходимости обладать специальными знаниями в области инфраструктуры для управления вычислительными экземплярами.
AWS SageMaker имеет более сложную кривую обучения , поскольку множество сервисов тесно связаны и объединены в единую систему для выполнения задач машинного обучения. Однако такой подход, ориентированный на задачи, обеспечивает четкое разделение между средами обучения и развертывания моделей, а также возможность распределенного обучения в масштабе. Предоставляя разработчикам больший контроль над инфраструктурой, SageMaker хорошо подходит для крупных команд, занимающихся анализом данных и искусственным интеллектом, с высоким уровнем зрелости MLOps и потребностью в конвейерах CI/CD.
Главный вывод
В этой серии статей мы сравниваем две самые популярные облачные платформы для масштабируемого обучения моделей — Azure и AWS, разбивая сравнение на следующие параметры:
- Управление проектами и получением разрешений
- хранение данных
- Вычислить
- Среда
В первой части мы обсудили основные аспекты настройки проекта и управления правами доступа, а затем поговорили о хранении и доступе к данным, необходимым для обучения модели.
AWS против Azure: подробный анализ обучения моделей — Часть 1
Во второй части мы рассмотрели, чем постоянные вычислительные ресурсы Azure ML, ориентированные на рабочее пространство, отличаются от подхода AWS SageMaker, основанного на предоставлении ресурсов по запросу и специфичного для конкретной задачи. Кроме того, мы изучили возможности настройки среды, от курируемых и пользовательских сред Azure до трех уровней настройки SageMaker — встроенный алгоритм, использование собственного скрипта, использование собственного контейнера. Это сравнение показывает модульную, удобную для начинающих архитектуру Azure ML по сравнению с интегрированной, ориентированной на задачи архитектурой SageMaker, которая предлагает большую масштабируемость и контроль над инфраструктурой для команд, которым требуются MLOps-решения.
Источник: towardsdatascience.com





















