И что это означает для генеративной оптимизации поисковых систем (GEO)
Делиться

Когда вы просите ChatGPT или Claude «поискать в интернете», он не просто отвечает на основе своих обучающих данных. Он вызывает отдельную поисковую систему.
Эту часть знают большинство людей.
Менее ясно, насколько важны традиционные поисковые системы и сколько всего было создано на их основе.
Не всё это полностью доступно публике, поэтому я делаю здесь умозаключения. Но мы можем использовать различные подсказки, полученные при рассмотрении более крупных систем, для построения полезной ментальной модели.
Мы рассмотрим оптимизацию запросов, то, как поисковые системы используются для обнаружения, группировки контента, поиска «на лету», а также то, как можно потенциально реверсировать систему, подобную этой, чтобы построить «систему оценки GEO [Generative Engine Optimization]».
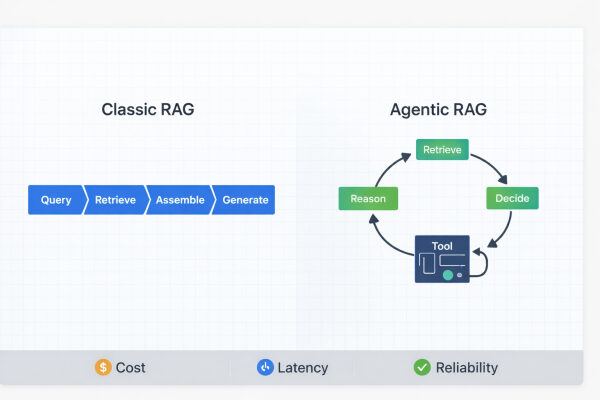
Если вы знакомы с RAG, то кое-что из этого покажется вам повторением, но все равно может быть полезно увидеть, как более крупные системы разделяют конвейер на фазу обнаружения и фазу извлечения.
Если у вас мало времени, вы можете прочитать краткий пересказ.
TL;DR
Веб-поиск в этих чат-ботах с искусственным интеллектом, вероятно, состоит из двух этапов. На первом этапе традиционные поисковые системы находят и ранжируют документы-кандидаты. На втором этапе они извлекают контент с этих URL-адресов и извлекают наиболее релевантные фрагменты, используя поиск на уровне фрагментов.
Главным изменением (по сравнению с традиционным SEO) является переписывание запросов и разбиение на фрагменты на уровне абзацев, что позволяет страницам с более низким рейтингом опережать страницы с более высоким рейтингом, если их отдельные абзацы лучше соответствуют вопросу.
Технический процесс
Компании, стоящие за Claude и ChatGPT, не полностью раскрывают, как работают их системы веб-поиска в чате пользовательского интерфейса, но, сложив все воедино, мы можем сделать много выводов.
Мы знаем, что они полагаются на поисковые системы для поиска кандидатов, и в таком масштабе было бы абсурдно не делать этого. Мы также знаем, что при обосновании своего ответа магистр права видит лишь фрагменты текста (отрывки или фрагменты).
Это явно намекает на некий тип поиска на основе встраивания по этим фрагментам, а не по целым страницам.
Этот процесс состоит из нескольких частей, поэтому мы рассмотрим его шаг за шагом.
Переписывание и разветвление запросов
Сначала мы рассмотрим, как система очищает запросы, отправленные человеком, и расширяет их. Мы рассмотрим этапы переписывания и разветвления, а также объясним, почему это важно как для разработки, так и для SEO.

Я думаю, что эта часть, возможно, наиболее прозрачна, и с ней, похоже, согласно большинство людей в сети.
Оптимизация запроса заключается в преобразовании человеческого запроса в более точный. Например, «пожалуйста, найдите те красные кроссовки, о которых мы говорили ранее» превращается в «коричнево-красные кроссовки Nike».
С другой стороны, этап разветвления предназначен для создания дополнительных вариантов. Например, если пользователь спрашивает о пешеходных маршрутах рядом со мной, система может попробовать что-то вроде «походы для начинающих рядом со Стокгольмом», «однодневные походы рядом со Стокгольмом с общественным транспортом» или «семейные маршруты рядом со Стокгольмом».
Это отличается от простого использования синонимов, для которого традиционные поисковые системы уже оптимизированы.
Если вы слышите об этом впервые и не уверены, взгляните на документацию Google по разветвлению запросов ИИ или немного поразмыслите о переписывании запросов.
Насколько это работает на самом деле, мы не знаем. Возможно, они не будут так сильно распылять данные и будут работать только с одним запросом, а затем, если результаты окажутся неудовлетворительными, отправят дополнительные запросы по конвейеру.
Можно сказать, что, вероятно, эту часть выполняет не какая-то большая модель. Если посмотреть на исследование, Йе и др. явно используют LLM для генерации сильных рерайтов, а затем перерабатывают их в более компактный рерайтер, чтобы избежать задержек и дополнительных затрат.
Что касается значения этой части конвейера, то для инженеров это просто означает, что вы хотите очистить беспорядочные человеческие запросы и превратить их во что-то с более высоким процентом результативности.
Для бизнесменов и SEO-специалистов это означает, что человеческие запросы, под которые вы оптимизировали свои поисковые системы, преобразуются в более роботизированные запросы в форме документов.
Насколько я понимаю, раньше SEO-специалисты уделяли большое внимание точному соответствию длинной фразы в заголовках. Если кто-то искал «лучшие кроссовки для бега при проблемах с коленями», вы бы придерживались именно этой строки.
Теперь вам также нужно заботиться о сущностях, атрибутах и отношениях.
Так, если пользователь просит «что-то для сухой кожи», в тексте могут быть такие варианты, как «увлажнитель», «окклюзионный», «увлажнитель», «керамиды», «без отдушек», «избегать спиртов», а не просто «как мне найти хорошее средство для сухой кожи».
Но давайте внесем ясность, чтобы не возникло путаницы: мы не можем видеть сами внутренние переписывания, так что это всего лишь примеры.
Если вам интересна эта часть, можете копнуть глубже. Уверен, есть множество статей о том, как это сделать правильно.
Давайте перейдем к тому, для чего на самом деле используются эти оптимизированные запросы.
Использование поисковых систем (для обнаружения на уровне документа)
Сейчас уже всем известно, что для получения актуальных ответов большинство ИИ-ботов используют традиционные поисковые системы. Это не всё, но это действительно сокращает объём интернета для работы.

Я предполагаю, что весь интернет слишком велик, слишком зашумлён и слишком быстро меняется, чтобы конвейер LLM мог напрямую извлекать необработанный контент. Поэтому, используя уже существующие поисковые системы, вы получаете возможность сузить область поиска.
Если взглянуть на более крупные конвейеры RAG, работающие с миллионами документов, то они делают нечто похожее. То есть используют своего рода фильтр, чтобы определить, какие документы важны и заслуживают дальнейшей обработки.
На этот счет у нас есть доказательства.
OpenAI и Anthropic заявили, что используют сторонние поисковые системы, такие как Bing и Brave, наряду с собственными поисковыми роботами.
К настоящему моменту Perplexity, возможно, уже самостоятельно построила эту часть, но вначале они сделали бы то же самое.
Мы также должны учитывать, что традиционные поисковые системы, такие как Google и Bing, уже решили самые сложные проблемы. Это устоявшаяся технология, которая отвечает за такие функции, как определение языка, оценка авторитетности, доверие доменов, фильтрация спама, проверка новизны, гео-предвзятость, персонализация и так далее.
Отказаться от всего этого и встроить весь веб самостоятельно — маловероятно. Поэтому, полагаю, они опираются на эти системы, а не перестраивают их.
Однако мы не знаем, сколько результатов они фактически выдают по запросу, будь то только первые 20 или только 30. В одной неофициальной статье сравнивались ссылки из ChatGPT и Bing, анализировался порядок ранжирования и выяснилось, что некоторые из них были с 22-го места. Если это правда, то вам следует стремиться к видимости в топ-20.
Более того, мы также не знаем, какие ещё метрики они используют для определения того, что именно будет опубликовано. В этой статье утверждается, что системы искусственного интеллекта отдают предпочтение заработанным медиа, а не официальным сайтам или соцсетям, так что это ещё не всё.
Тем не менее, задача поисковой системы (будь то полностью сторонняя или смешанная) — обнаружение. Она ранжирует URL-адреса на основе авторитетности и ключевых слов. Она может включать фрагмент информации, но одного этого будет недостаточно для ответа на вопрос.
Если бы модель опиралась только на фрагмент, заголовок и URL, она, вероятно, искажала бы детали. Этого контекста недостаточно.
Таким образом, это подталкивает нас к двухэтапной архитектуре, где этап извлечения уже встроен, и к нему мы скоро вернемся.
Что это означает с точки зрения SEO?
Это значит, что вам всё равно нужно занимать высокие позиции в традиционных поисковых системах, чтобы попасть в первоначальный пакет обрабатываемых документов. Так что да, классическое SEO по-прежнему важно.
Но это также может означать, что вам следует подумать о потенциальных новых метриках, которые они могут использовать для ранжирования этих результатов.
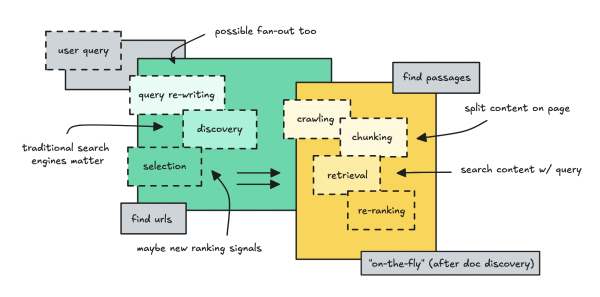
На этом этапе мы сужаем область поиска до нескольких страниц, которые стоит изучить, используя как проверенные поисковые технологии, так и внутренние инструменты. Всё остальное (часть «возвращает фрагменты информации») происходит после этого этапа с использованием стандартных методов поиска.
Ползать, отрывать и извлекать
Теперь перейдем к тому, что происходит, когда система выявляет несколько интересных URL-адресов.
Как только небольшой набор URL-адресов проходит первый фильтр, процесс становится довольно простым: сканируем страницу, разбиваем её на фрагменты, встраиваем эти фрагменты, извлекаем те, которые соответствуют запросу, и затем переранжируем их. Это называется извлечением.

Я называю это «на лету», потому что система встраивает фрагменты только после того, как URL становится кандидатом, а затем кэширует эти встраивания для повторного использования. Эта часть может быть новой, если вы уже знакомы с поиском.
Для сканирования страницы они используют собственные поисковые роботы. Для OpenAI это OAI-SearchBot, который извлекает необработанный HTML-код для обработки. Поисковые роботы не выполняют JavaScript. Они используют HTML-код, отрендеренный сервером, поэтому к ним применяются те же правила SEO: контент должен быть доступен.
После извлечения HTML-кода его содержимое необходимо преобразовать в нечто, пригодное для поиска.
Если вы новичок, вам может показаться, что ИИ «сканирует документ», но это не так. Сканирование целых страниц за один запрос было бы слишком медленным и затратным.
Вместо этого страницы разбиваются на фрагменты, обычно в соответствии со структурой HTML: заголовки, абзацы, списки, разрывы разделов и т.п. В контексте поиска они называются фрагментами.
Каждый фрагмент становится небольшой, самостоятельным блоком. Если говорить о токенах, то, судя по ссылкам в интерфейсе Perplexity, фрагменты состоят из десятков токенов, возможно, около 150, а не 1000. Это примерно 110–120 слов.
После разделения на фрагменты эти элементы встраиваются с использованием как разреженных, так и плотных векторов. Это позволяет системе выполнять гибридный поиск и сопоставлять запрос как семантически, так и по ключевым словам.
Если вы новичок в семантическом поиске, то, короче говоря, это означает, что система ищет по смыслу, а не по точным словам. Поэтому запросы вроде «симптомы дефицита железа» и «признаки дефицита железа в вашем организме» всё равно будут располагаться рядом в пространстве вложений. Подробнее о вложениях можно прочитать здесь, если вам интересно, как это работает.
После того, как популярная страница была разделена на фрагменты и внедрена, эти вставки, вероятно, кэшируются. Никто не будет встраивать один и тот же ответ StackOverflow тысячи раз в день.
Очевидно, именно поэтому система кажется такой быстрой: вероятно, 95–98% цитируемого веб-контента уже встроены и активно кэшируются.
Однако мы не знаем, в какой степени и сколько они предварительно встраиваются, чтобы гарантировать быструю работу системы для популярных запросов.
Теперь системе нужно определить, какие фрагменты текста имеют значение. Она использует вложения для каждого фрагмента текста, чтобы вычислить оценку как семантического, так и ключевого соответствия.
Система выбирает фрагменты с наивысшими оценками. Это может быть от 10 до 50 фрагментов с наивысшими оценками.
После этого большинство развитых систем будут использовать рераннер (перекрёстный кодировщик) для повторной обработки этих верхних фрагментов, выполняя ещё один раунд ранжирования. Это этап «исправления ошибок поиска», поскольку, к сожалению, поиск не всегда абсолютно надёжен по многим причинам.
Хотя они ничего не говорят об использовании кросс-кодера, Perplexity — одна из немногих компаний, которая открыто документирует свой процесс извлечения данных.
Их API поиска утверждает, что они «делят документы на мелкие единицы» и оценивают эти единицы по отдельности, чтобы иметь возможность возвращать «наиболее релевантные фрагменты, уже ранжированные».
Что всё это значит для SEO? Если система использует такой поиск, ваша страница не воспринимается как один большой массив данных.
Текст разбивается на части (часто на уровне абзацев или заголовков), и именно эти части оцениваются. В процессе поиска важна вся страница целиком, но после начала поиска важны именно отдельные части.
Это означает, что каждый фрагмент должен отвечать на вопрос пользователя.
Это также означает, что если важная информация не содержится в едином фрагменте, система может потерять контекст. Поиск — это не магия. Модель никогда не видит вашу страницу целиком.
Итак, мы рассмотрели этап поиска: система сканирует страницы, разбивает их на блоки, встраивает эти блоки, а затем использует гибридный поиск и повторное ранжирование, чтобы извлечь только те отрывки, которые могут ответить на вопрос пользователя.
Выполняю еще один проход и передаю части в LLM
Теперь перейдем к тому, что происходит после этапа извлечения, включая функцию «продолжения поиска» и передачу фрагментов основному LLM.

После того, как система определила несколько фрагментов высокого ранга, ей необходимо решить, достаточно ли они хороши или нужно продолжить поиск. Это решение почти наверняка принимает небольшая модель контроллера, а не основной модуль управления базой данных (LLM).
Я лишь предполагаю, но если материал кажется скудным или не по теме, он может запустить ещё один раунд поиска. Если же он выглядит убедительным, он может передать эти фрагменты LLM.
В какой-то момент происходит эта передача. Выбранные фрагменты вместе с некоторыми метаданными передаются основному LLM.
Модель считывает все предоставленные фрагменты и выбирает тот, который лучше всего соответствует ответу, который она хочет сгенерировать.
Он не следует автоматически порядку, заданному ретривером. Поэтому нет гарантии, что LLM будет использовать «верхний» фрагмент. Он может предпочесть отрывок с более низким рейтингом просто потому, что он понятнее, более самостоятелен или ближе к формулировке, необходимой для ответа.
Так же, как и мы, он решает, что принять во внимание, а что проигнорировать. И даже если ваш фрагмент наберёт наивысший балл, нет гарантии, что он будет упомянут первым.
О чем думать
Эта система — не просто чёрный ящик. Это система, созданная для того, чтобы предоставить магистрам права (LLM) необходимую информацию для ответа на вопрос пользователя.
Если то, что я предположил, правда, то он находит кандидатов, разбивает документы на блоки, ищет и ранжирует эти блоки, а затем передает их LLM для подведения итогов.
Отсюда мы также можем понять, о чем нам следует думать при создании контента для него.
Традиционное SEO по-прежнему имеет большое значение, поскольку эта система опирается на старую. Такие факторы, как правильная карта сайта, легкость отображения контента, корректные заголовки, авторитетность домена и корректные теги последнего изменения, важны для корректной сортировки вашего контента.
Как я уже указывал, они могут смешивать поисковые системы со своими собственными технологиями, чтобы решить, какие URL-адреса выбрать, и об этом стоит помнить.
Но если они используют поиск поверх этого, то релевантность на уровне абзацев становится новой точкой воздействия.
Возможно, это означает, что дизайн «ответ в одном фрагменте» будет главенствовать. (Только не делайте это так, чтобы это выглядело странно, возможно, вкратце.) И не забывайте использовать правильную терминологию: сущности, атрибуты, отношения, как мы говорили в разделе об оптимизации запросов.
Как создать «систему оценки GEO» (для развлечения)
Чтобы выяснить, насколько хорошо будет работать ваш контент, нам придется смоделировать враждебную среду, в которой он будет существовать. Давайте попробуем провести обратную разработку этого конвейера.
Обратите внимание, это нетривиально, поскольку мы не знаем, какие внутренние показатели они используют, и эта система не является полностью публичной, поэтому воспринимайте это как приблизительный план.
Идея заключается в создании конвейера, который может выполнять переписывание запросов, обнаружение, извлечение, повторное ранжирование и оценку LLM, а затем посмотреть, где вы окажетесь по сравнению с вашими конкурентами по различным темам.

Вы начинаете с нескольких тем, например «гибридный поиск для корпоративного RAG» или «оценивание LLM с LLM-как-судьей», а затем создаете систему, которая генерирует естественные запросы вокруг них.
Затем вы пропускаете эти запросы через этап переписывания LLM, поскольку эти системы часто переформулируют пользовательский запрос перед извлечением. Именно эти переписанные запросы вы и продвигаете по конвейеру.
Первая проверка — видимость. По каждому запросу просмотрите первые 20–30 результатов в Brave, Google и Bing. Обратите внимание, отображается ли ваша страница и какое место она занимает относительно конкурентов.
В то же время собирайте показатели авторитетности на уровне домена (Moz DA, Ahrefs DR и т. д.), чтобы иметь возможность учитывать их позже, поскольку эти системы, вероятно, по-прежнему в значительной степени опираются на эти сигналы.
Если ваша страница появилась в этих первых результатах, вы переходите к этапу поиска.
Возьмите свою страницу и страницы-конкуренты, очистите HTML-код, разделите их на фрагменты, встройте эти фрагменты и создайте небольшую гибридную систему поиска, сочетающую семантическое и ключевое соответствие. Добавьте этап повторного ранжирования.
Где-то здесь вы также внедряете сигнал авторитетности, поскольку домены с более высоким авторитетом действительно получают более высокий рейтинг (хотя мы и не знаем точно, насколько).
После того, как вы определили лучшие фрагменты, вы добавляете последний уровень: магистра права (LLM) в качестве судьи. Попадание в пятёрку лучших не гарантирует цитирования, поэтому вы имитируете последний этап, передавая магистрам права (LLM) несколько наиболее оцененных фрагментов (с некоторыми метаданными) и смотрите, какой из них он процитирует первым.
При запуске этого метода для ваших страниц и страниц конкурентов вы увидите, где вы выигрываете или проигрываете: на уровне поиска, на уровне извлечения или на уровне LLM.
Помните, что это всего лишь грубый набросок, но он даст вам отправную точку, если вы захотите построить подобную систему.
Источник: towardsdatascience.com