
Часть 1: Что такое статистическая мощность и как ее вычислить?
Делиться

Введение
Показать код библиотека(tibble) библиотека(ggplot2) библиотека(dplyr) библиотека(tidyr) библиотека(latex2exp) библиотека(scales) библиотека(knitr)
За последние несколько лет работы в сфере маркетинговых измерений я заметил, что анализ мощности — одна из самых малоизученных тем в тестировании и измерении. Иногда его понимают неправильно, а иногда и вовсе не применяют, несмотря на его основополагающую роль в разработке тестов. Эта статья и серия последующих статей — мои попытки развеять эту мысль.
В этом сегменте я расскажу:
- Что такое статистическая мощность?
- Как это вычислить?
- Что может влиять на власть?
Анализ мощности — это статистическая тема, и, как следствие, в ней будет математика и статистика (сумасшедшая идея, правда?), но я постараюсь связать эти технические детали с реальными проблемами или базовой интуицией, когда это возможно.
Без лишних слов, давайте перейдем к делу.
Типы ошибок при тестировании: тип I и тип II
При тестировании возможны два типа ошибок:
- Тип I :
- Техническое определение: Мы ошибочно отвергаем нулевую гипотезу, когда нулевая гипотеза верна.
- Определение для неспециалиста: мы говорим, что был эффект, когда на самом деле его не было.
- Пример: A/B-тестирование нового креатива и заключение, что он работает лучше старого дизайна, хотя на самом деле оба дизайна работают одинаково.
- Тип II :
- Техническое определение: Мы не можем отвергнуть нулевую гипотезу, если нулевая гипотеза ложна.
- Определение для неспециалиста: мы говорим, что не было никакого эффекта, когда на самом деле он был
- Пример: A/B-тестирование нового креатива и заключение, что он работает так же, как и старый дизайн, хотя на самом деле новый дизайн работает лучше.
Что такое статистическая мощность?
Большинство людей знакомы с ошибкой первого рода. Это ошибка, которую мы контролируем, устанавливая уровень значимости. Мощность связана с ошибкой второго рода. Более конкретно, мощность — это вероятность правильного отклонения нулевой гипотезы, когда она ложна. Она является дополнением к ошибке второго рода (то есть 1 — ошибка второго рода). Другими словами, мощность — это вероятность обнаружения истинного эффекта, если он существует. Должно быть понятно, почему это важно:
- Недостаточно мощные тесты, скорее всего, не смогут выявить истинные эффекты, что приведет к упущенным возможностям для улучшения.
- Недостаточно мощные тесты могут привести к ложной уверенности в результатах, поскольку мы можем сделать вывод, что эффекта нет, хотя на самом деле он есть.
- … и, что самое простое, тесты с недостаточной мощностью приводят к потере денег и ресурсов
Роль α и β
Если оба важны, почему ошибка типа II и мощность так неправильно понимаются и игнорируются, в то время как тип I всегда рассматривается? Это потому, что мы можем легко выбрать наш уровень ошибок типа I. Фактически, это именно то, что мы делаем, когда устанавливаем уровень значимости α (обычно α = 0,05) для наших тестов. Мы заявляем, что нас устраивает определенный процент ошибок типа I. Во время настройки теста мы делаем утверждение: «нас устраивает уровень ложноположительных результатов X %», а затем устанавливаем α = X %. После теста, если наше p-значение падает ниже α, мы отвергаем нулевую гипотезу (т. е. «результаты значимы»), а если p-значение падает выше α, мы не отвергаем нулевую гипотезу (т. е. «результаты незначимы»).
Определить ошибку второго рода, β (обычно β = 0,20), и, следовательно, мощность, не так просто. Для этого требуется сделать предположения и провести анализ, называемый «анализом мощности». Чтобы понять процесс, лучше сначала пройти весь процесс тестирования, а затем вернуться к нему, чтобы понять, как можно вычислить мощность и повлиять на неё. Давайте рассмотрим в качестве примера простой креативный A/B-тест.
| Концепция | Символ | Типичные значения | Техническое определение | Определение на простом языке |
|---|---|---|---|---|
| Ошибка типа I | α | 0,05 (5%) | Вероятность отклонения нулевой гипотезы, когда нулевая гипотеза на самом деле верна | Говорить о наличии эффекта, когда на самом деле нет никакой разницы |
| Ошибка типа II | β | 0,20 (20%) | Вероятность не отвергнуть нулевую гипотезу, когда нулевая гипотеза на самом деле ложна | Говорить, что нет никакого эффекта, когда на самом деле он есть |
| Власть | 1 − β | 0,80 (80%) | Вероятность правильного отклонения нулевой гипотезы, когда верна альтернатива | Вероятность того, что мы обнаружим истинный эффект, если он есть, |
Вычислительная мощность: шаг за шагом
Прежде чем мы начнем, несколько замечаний:
- Я сделал несколько допущений и приблизительных значений для упрощения примера. Если вы их заметили — отлично. Если нет — не беспокойтесь. Цель — понять концепции и процесс, а не мелкие детали.
- Я называю порог принятия решения в пространстве z-значений критическим значением. Критическое значение обычно относится к порогу в исходном пространстве (например, коэффициенты конверсии), но я буду использовать его как взаимозаменяемый термин, чтобы не вводить новый.
- В статье присутствуют фрагменты кода, связанные с текстом и концепциями. Скопировав код, вы можете поэкспериментировать с параметрами и посмотреть, как он изменится. Некоторые фрагменты кода скрыты для удобства чтения. Нажмите «Показать код», чтобы увидеть код.
- Попробуйте следующее: измените размер выборки в настройках теста так, чтобы тестовая статистика была чуть ниже критического значения, а затем выполните анализ мощности. Соответствуют ли результаты вашим ожиданиям?
Тестовая настройка и статистика теста
Как уже говорилось, лучше всего сначала пройти весь процесс тестирования, а затем вернуться к нему, чтобы понять, как можно рассчитать мощность. Давайте так и сделаем.
# Задайте параметры для теста A/B N_a <- 1000 # Размер выборки для креатива A N_b <- 1000 # Размер выборки для креатива B альфа <- 0,05 # Уровень значимости # Функция для вычисления критического z-значения для одностороннего теста critic_z <- function(alpha, two_sided = FALSE) { if (two_sided) qnorm(1 - alpha/2) else qnorm(1 - alpha) }
Как уже говорилось, лучше всего сначала пройти весь процесс тестирования, а затем вернуться к нему, чтобы понять, как можно рассчитать мощность. Давайте так и сделаем.
Наша тестовая установка:
- Нулевая гипотеза : Коэффициент конверсии А равен коэффициенту конверсии В.
- Альтернативная гипотеза : Коэффициент конверсии B больше, чем коэффициент конверсии A.
- Размер выборки :
- Na = 1000 — Количество людей, которые получают креатив А
- Nb = 1000 — Количество людей, получивших креатив B
- Уровень значимости : α = 0,05
- Критическое значение : критическое значение — это z-оценка, соответствующая уровню значимости α. Мы называем её Z1−α. Для одностороннего теста с α = 0,05 это значение приблизительно равно 1,64.
- Тип теста : двухпропорциональный z-тест
x_a <- 100 # Количество конверсий для креатива A x_b <- 150 # Количество конверсий для креатива B p_a <- x_a / N_a # Коэффициент конверсии для креатива A p_b <- x_b / N_b # Коэффициент конверсии для креатива B
Наши результаты:
- xa = 100 — Количество конверсий из креатива A
- xb = 150 — Количество конверсий из креатива B
- pa = xa / Na = 0,10 — Коэффициент конверсии креатива A
- pb = xb / Nb = 0,15 — Коэффициент конверсии креатива B
При нулевой гипотезе разница в коэффициентах конверсии следует приблизительно нормальному распределению со следующим образом:
- Среднее: μ = 0 (нет разницы в коэффициентах конверсии)
- Стандартное отклонение:
σ = √[ pa(1 − pa)/Na + pb(1 − pb)/Nb ] ≈ 0,01
z_score <- function(p_a, p_b, N_a, N_b) { (p_b - p_a) / sqrt((p_a * (1 - p_a) / N_a) + (p_b * (1 - p_b) / N_b)) }
Из этих значений мы можем вычислить тестовую статистику:
[
z = frac{p_b – p_a}
{sqrt{frac{p_a (1 – p_a)}{N_a} + frac{p_b (1 – p_b)}{N_b}}}
приблизительно 3,39
]
Если наша тестовая статистика z больше критического значения, мы отвергаем нулевую гипотезу и приходим к выводу, что креатив B работает лучше, чем креатив A. Если z меньше или равно критическому значению, мы не отвергаем нулевую гипотезу и приходим к выводу, что между двумя креативами нет существенной разницы.
Другими словами, если наши результаты вряд ли будут наблюдаться, когда коэффициенты конверсии A и B действительно одинаковы, мы отвергаем нулевую гипотезу и утверждаем, что креатив B работает лучше, чем креатив A. В противном случае мы не отвергаем нулевую гипотезу и утверждаем, что между двумя креативами нет существенной разницы.
Учитывая результаты нашего теста, мы отвергаем нулевую гипотезу и приходим к выводу, что Creative B работает лучше, чем Creative A.
z <- z_score(p_a, p_b, N_a, N_b) критическое_значение <- критическое_z(альфа) if (z > критическое_значение) { result <- "Отклонить нулевую гипотезу: Креатив B работает лучше, чем Креатив A" } else { result <- "Невозможно отклонить нулевую гипотезу: нет существенной разницы между креативами" } result #> [1] «Отклонить нулевую гипотезу: Креатив B работает лучше, чем Креатив A»
Интуиция, стоящая за властью
Теперь, когда мы разобрались с процессом тестирования, где же в игру вступает мощность? В описанном выше процессе мы регистрируем показатели конверсии выборки pa и pb, а затем вычисляем статистику теста z. Однако, если бы мы повторили тест много раз, мы бы получили разные показатели конверсии выборки и разные статистические данные теста, основанные на реальных показателях конверсии креативов.
Предположим, что истинный коэффициент конверсии креатива B выше, чем у креатива A. Некоторые из этих тестов всё равно не смогут опровергнуть нулевую гипотезу из-за естественной дисперсии. Мощность — это процент этих тестов, которые отвергают нулевую гипотезу. Это базовый механизм любого анализа мощности, который указывает на недостающий компонент: истинные коэффициенты конверсии или, в более общем смысле, истинную величину эффекта.
Интуитивно понятно, что если истинный размер эффекта выше, то и измеренный нами эффект, как правило, будет выше, и мы будем чаще отвергать нулевую гипотезу, тем самым увеличивая мощность.
Выбор истинного размера эффекта
Если нам нужны истинные коэффициенты преобразования для вычисления мощности, как их получить? Если бы они были, нам не пришлось бы проводить тестирование. Поэтому нам нужно сделать предположение. В целом, существует два подхода:
- Выберите значимый размер эффекта: в этом подходе мы присваиваем истинный размер эффекта (или истинную разницу в коэффициентах конверсии) уровню, который будет значимым. Если бы Creative B увеличил коэффициент конверсии всего на 0,01%, разве это нас бы волновало и мы бы приняли меры в связи с этими результатами? Вероятно, нет. Так почему же нам важно иметь возможность обнаружить такой незначительный эффект? С другой стороны, если бы Creative B увеличил коэффициент конверсии на 50%, нас бы это, безусловно, волновало. На практике значимый размер эффекта, вероятно, находится между этими двумя точками.
- Примечание: Это часто называют минимальным обнаруживаемым эффектом. Однако минимальный обнаруживаемый эффект исследования и минимальный обнаруживаемый эффект, который нас интересует (например, нас может интересовать только 5% или более эффектов, но исследование предназначено для выявления 1% или более эффектов), могут различаться. По этой причине я предпочитаю использовать термин «значимый эффект» применительно к данной стратегии.
- Использование предыдущих исследований: если у нас есть данные предыдущих исследований или моделей, которые измеряют эффективность этого креатива или подобных креативов, мы можем использовать эти значения для определения истинного размера эффекта.
Оба вышеприведенных подхода являются правомерными.
Если вам важно увидеть только значимые эффекты и вы не против упустить менее значимые, выберите первый вариант. Если же вам необходимо увидеть «статистическую значимость», выберите второй вариант и будьте осторожны с используемыми значениями (подробнее об этом в другой статье).
Техническое примечание
Поскольку у нас нет истинных коэффициентов конверсии, мы технически присваиваем альтернативной гипотезе определённое ожидаемое распределение и затем вычисляем мощность на его основе. Истинное среднее значение в следующих отрывках технически является ожидаемым средним значением в рамках альтернативной гипотезы. Я буду использовать термин «истинный» для простоты и краткости.
Вычислительная и визуализационная мощность
Теперь, когда у нас есть недостающие ингредиенты, истинные коэффициенты преобразования, мы можем вычислить мощность. Вместо измеренных значений pa и pb у нас теперь есть истинные коэффициенты преобразования ra и rb.
Мы измеряем мощность как:
[
1 – бета = 1 – P(z < Z_{1-альфа} ;|; N_a, N_b, r_a, r_b)
]
На первый взгляд это может показаться запутанным, поэтому давайте разберемся.
Мы утверждаем, что мощность (1 − β) вычисляется путём вычитания коэффициента ошибки типа II из единицы. Коэффициент ошибки типа II — это вероятность того, что результат теста окажется ниже нашего порога значимости, учитывая размер выборки и истинные коэффициенты конверсии ra и rb. Как вычислить эту последнюю часть?
В двухпропорциональном тесте z-оценки мы знаем, что:
- Среднее: μ = rb − ra
- Стандартное отклонение: σ = √[ ra(1 — ra)/Na + rb(1 — rb)/Nb ]
Теперь нам нужно вычислить:
[
P(X > Z_{1-alpha}), quad X sim N!left(frac{mu}{sigma},,1right)
]
Это область под приведенным выше распределением, которая находится справа от Z1−α и эквивалентна вычислению:
[
P!left(X > frac{mu}{sigma} – Z_{1-alpha}right), quad X sim N(0,1)
]
Если бы у нас был учебник с таблицей z-оценок, мы могли бы просто найти p-значение, связанное с
(μ / σ − Z1−α), и это даст нам мощность.
Давайте покажем это наглядно:
Покажите код r_a <- p_a # истинный базовый коэффициент конверсии; мы повторно используем измеренное значение r_b <- p_b # истинный коэффициент конверсии лечения; мы повторно используем значение меры alpha <- 0.05 two_sided <- FALSE # устанавливаем TRUE для двустороннего теста mu_diff <- function(r_a, r_b) r_b - r_a sigma_diff <- function(r_a, r_b, N_a, N_b) { sqrt(r_a*(1 - r_a)/N_a + r_b*(1 - r_b)/N_b) } power_value <- function(r_a, r_b, N_a, N_b, alpha, two_sided = FALSE) { mu <- mu_diff(r_a, r_b) sd1 <- sigma_diff(r_a, r_b, N_a, N_b) zc <- critic_z(alpha, two_sided) thr <- zc * sigma_diff(r_a, r_b, N_a, N_b) if (!two_sided) { 1 - pnorm(thr, mean = mu, sd = sd1) } else { pnorm(-thr, mean = mu, sd = sd1) + (1 - pnorm(thr, mean = mu, sd = sd1)) } } # Построить график данных mu <- mu_diff(r_a, r_b) sd1 <- sigma_diff(r_a, r_b, N_a, N_b) zc <- critic_z(alpha, two_sided) thr <- zc * sigma_diff(r_a, r_b, N_a, N_b) # x-диапазон, охватывающий как кривые, так и пороговые значения x_min <- min(-4*sd1, mu - 4*sd1, -thr) - 0.1*sd1 x_max <- max( 4*sd1, mu + 4*sd1, thr) + 0.1*sd1 xx <- seq(x_min, x_max, length.out = 2000) df <- tibble( x = xx, H0 = dnorm(xx, mean = 0, sd = sd1), # распределение, используемое пороговым значением теста H1 = dnorm(xx, mean = mu, sd = sd1) # истинное (альтернативное) распределение ) # Регионы для затенения для мощности if (!two_sided) { shade <- df %>% filter(x >= thr) } else { shade <- bind_rows( df %>% filter(x >= thr), df %>% filter(x <= -thr) ) } # Числовая мощность для подзаголовка pow <- power_value(r_a, r_b, N_a, N_b, alpha, two_sided) # График ggplot(df, aes(x = x)) + # Затененная область мощности H1 geom_area( data = shade, aes(y = H1), alpha = 0.25 ) + # Кривые geom_line(aes(y = H0), linewidth = 1) + geom_line(aes(y = H1), linewidth = 1, linetype = "dashed") + # Критические линии geom_vline(xintercept = thr, linetype = "dotted", linewidth = 0.8) + { if (two_sided) geom_vline(xintercept = -thr, linetype = "dotted", linewidth = 0.8) } + # Средние маркеры geom_vline(xintercept = 0, alpha = 0.3) + geom_vline(xintercept = mu, alpha = 0.3, linetype = "dashed") + # Метки labs( title = "Мощность как затененная область под H1 за пределами критического порога", subtitle = TeX(sprintf(r"($1 - beta$ = %.1f%% | $mu$ = %.4f, $sigma$ = %.4f, $z^*$ = %.3f, threshold = %.4f)", 100*pow, mu, sd1, zc, thr)), x = TeX(r"(Разница в коэффициентах конверсии ($D = p_b - p_a$))"), y = "Плотность" ) + annotate("текст", x = mu, y = max(df$H1)*0.95, label = TeX(r"(H1: $N(mu, sigma^2)$)"), hjust = -0.05) + annotate("текст", x = 0, y = max(df$H0)*0.95, label = TeX(r"(H0: $N(0, sigma^2)$)"), hjust = 1.05) + theme_minimal(base_size = 13)
На представленном выше графике мощность — это площадь под альтернативным распределением (H1) (где мы предполагаем, что альтернатива распределена в соответствии с нашими истинными коэффициентами конверсии), которая находится за пределами критического порога (т.е. области, где мы отвергаем нулевую гипотезу). При заданных нами параметрах мощность составляет 0,96. Это означает, что при многократном повторении этого теста с теми же параметрами мы могли бы ожидать отклонения нулевой гипотезы примерно в 96% случаев.
Кривые мощности
Теперь, когда у нас есть интуиция и математические расчёты, мы можем исследовать, как мощность меняется в зависимости от различных параметров. Графики, полученные в результате такого анализа, называются кривыми мощности.
Примечание
На графиках вы заметите, что выделено значение мощности 80%. Это распространённый целевой показатель мощности при тестировании, поскольку он позволяет сбалансировать риск ошибки II типа с затратами на увеличение размера выборки или корректировку других параметров. В результате это значение будет выделено во многих программных пакетах.
Связь с размером эффекта
Ранее я утверждал, что чем больше размер эффекта, тем выше мощность. Интуитивно это понятно. По сути, мы сдвигаем правую кривую нормального распределения на представленном выше графике вправо, поэтому область за критическим порогом увеличивается. Давайте проверим эту теорию.
Покажите код # Функция для вычисления мощности для различных размеров эффекта power_curve <- function(effect_sizes, N_a, N_b, alpha, two_sided = FALSE) { sapply(effect_sizes, function(e) { r_a <- p_a r_b <- p_a + e # Отрегулируйте r_b на основе размера эффекта power_value(r_a, r_b, N_a, N_b, alpha, two_sided) }) } # Сгенерируйте размеры эффекта effect_sizes <- seq(0, 0.1, length.out = 100) # Размеры эффекта от 0 до 10% # Вычислите мощность для каждого размера эффекта power_values <- power_curve(effect_sizes, N_a, N_b, alpha) # Создайте фрейм данных для построения графика power_df <- tibble( effect_size = effect_sizes, power = power_values ) # Постройте кривую мощности ggplot(power_df, aes(x = effect_size, y = power)) + geom_line(color = "blue", size = 1) + geom_hline(yintercept = 0.80, linetype = "dashed", alpha = 0.6) + # целевая мощность guide labs( title = "Мощность против размера эффекта", x = TeX(r"(Размер эффекта ($r_b - r_a$))"), y = TeX(r'(Мощность ($1 - beta $))')) + scale_x_continuous(labels = scales::percent_format(точность = 0.01)) + scale_y_continuous(labels = scales::percent_format(точность = 1), limits = c(NA,1)) + theme_minimal(base_size = 13)
Теория подтверждена: с увеличением размера эффекта мощность увеличивается. Она приближается к 100% по мере увеличения размера эффекта и смещения порога принятия решения вниз по длинному хвосту нормального распределения.
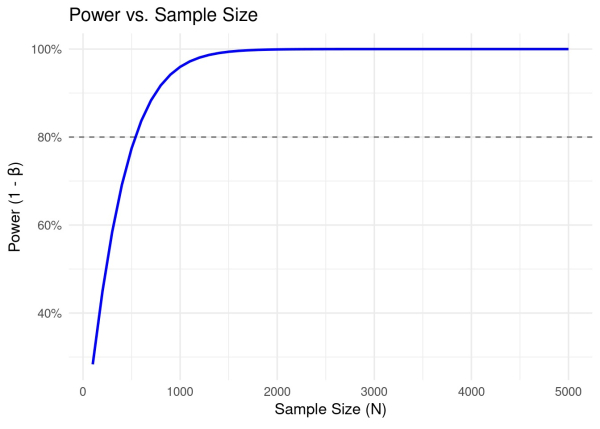
Связь с размером выборки
К сожалению, мы не можем контролировать размер эффекта. Он зависит либо от значимого размера эффекта, который вы хотите обнаружить, либо от размера эффекта, основанного на предыдущих исследованиях. Он такой, какой есть. Мы можем контролировать размер выборки. Чем больше размер выборки, тем меньше стандартное отклонение распределения и тем больше площадь под кривой за пределами критического порога (представьте, что вы сжимаете стороны, чтобы сжать колоколообразные кривые на графике выше). Другими словами, больший размер выборки должен приводить к большей мощности. Давайте проверим и эту теорию.
Покажите код power_sample_size <- function(N_a, N_b, r_a, r_b, alpha, two_sided = FALSE) { power_value(r_a, r_b, N_a, N_b, alpha, two_sided) } # Сгенерировать размеры выборки sample_sizes <- seq(100, 5000, by = 100) # Размеры выборки от 100 до 5000 # Вычислить мощность для каждого размера выборки power_values_sample <- sapply(sample_sizes, function(N) { power_sample_size(N, N, r_a, r_b, alpha) }) # Создать фрейм данных для построения графика power_sample_df <- tibble( sample_size = sample_sizes, power = power_values_sample ) # Построить кривую мощности для различных размеров выборки ggplot(power_sample_df, aes(x = sample_size, y = power)) + geom_line(color = "blue", size = 1) + geom_hline(yintercept = 0.80, linetype = "dashed", alpha = 0.6) + # целевая мощность guide labs( title = "Мощность против размера выборки", x = TeX(r"(Размер выборки ($N$))"), y = TeX(r"(Мощность (1 - $beta$))") ) + scale_y_continuous(labels = scales::percent_format(точность = 1), пределы = c(NA,1)) + theme_minimal(base_size = 13)
Мы снова видим ожидаемую зависимость: с увеличением размера выборки увеличивается мощность.
Примечание
В данной конкретной конфигурации мы можем повысить мощность, увеличив размер выборки. В более общем смысле, это означает повышение точности. В других конфигурациях тестирования точность, а следовательно, и мощность, можно повысить другими способами. Например, в геотестировании мы можем повысить точность, выбирая предсказуемые рынки или включая экзогенные характеристики (подробнее об этом в следующей статье).
Связь с уровнем значимости
Влияет ли уровень значимости α на мощность? Интуитивно понятно, что чем более мы готовы принять ошибку первого рода, тем более вероятно, что мы отвергнем нулевую гипотезу, и, следовательно, (1 − β) должно быть выше. Давайте проверим эту теорию.
Показать код power_of_alpha <- function(alpha_vec, r_a, r_b, N_a, N_b, two_sided = FALSE) { sapply(alpha_vec, function(a) power_value(r_a, r_b, N_a, N_b, a, two_sided) ) } alpha_grid <- seq(0.001, 0.20, length.out = 400) power_grid <- power_of_alpha(alpha_grid, r_a, r_b, N_a, N_b, two_sided) # Текущая точка power_now <- power_value(r_a, r_b, N_a, N_b, alpha, two_sided) df_alpha_power <- tibble(alpha = alpha_grid, power = power_grid) ggplot(df_alpha_power, aes(x = alpha, y = мощность)) + geom_line(color = "blue", size = 1) + geom_hline(yintercept = 0.80, linetype = "dashed", alpha = 0.6) + # целевое руководство по мощности geom_vline(xintercept = alpha, linetype = "dashed", alpha = 0.6) + # ваша альфа scale_x_continuous(labels = scales::percent_format(accuracy = 1)) + scale_y_continuous(labels = scales::percent_format(accuracy = 1), limits = c(NA,1)) + labs( title = TeX(r"(Мощность против уровня значимости)"), subtitle = TeX(sprintf(r"(At $alpha$ = %.1f%%, $1 - beta$ = %.1f%%)", 100*alpha, 100*power_now)), x = TeX(r"(Уровень значимости ($alpha$))"), y = TeX(r"(Мощность (1 - $beta$))") ) + theme_minimal(base_size = 13)
И снова результаты соответствуют нашей интуиции. В статистике бесплатных обедов не бывает. При прочих равных условиях, если мы хотим снизить частоту ошибок второго рода (β), мы должны быть готовы принять более высокую частоту ошибок первого рода (α).
Анализ мощности
Итак, что же такое анализ мощности? Анализ мощности — это процесс вычисления мощности с учётом параметров теста. В анализе мощности мы фиксируем параметры, которые не можем контролировать, а затем оптимизируем контролируемые параметры для достижения желаемого уровня мощности. Например, мы можем зафиксировать истинный размер эффекта, а затем рассчитать размер выборки, необходимый для достижения желаемого уровня мощности. Кривые мощности часто используются для облегчения процесса принятия решений. Далее в этой серии я подробно рассмотрю анализ мощности на примере из реальной практики.
Источники
[1] Р. Ларсен и М. Маркс, Введение в математическую статистику и ее приложения
Что дальше в серии?
Я еще окончательно не решил, но я определенно хочу осветить следующие темы:
- Анализ мощности в геотестировании
- Подробное руководство по установке истинного размера эффекта в различных контекстах
- Реальные примеры сквозного взаимодействия
Буду рад услышать ваши идеи. Обращайтесь. Мои контактные данные указаны ниже:
- Электронная почта: [email protected]
- LinkedIn: Сэм Аррингтон
Источник: towardsdatascience.com





















