
Узнайте, как обрабатывать потоковые данные в MS Fabric
Делиться

Когда-то обработка потоковых данных считалась передовым подходом. С появлением реляционных систем управления базами данных в 1970-х годах и традиционных систем хранения данных в конце 1980-х годов все рабочие процессы с данными начинались и заканчивались так называемой пакетной обработкой. Пакетная обработка основана на концепции объединения множества задач в группу (или пакет) и выполнения этих задач за одну операцию.
С другой стороны, существует концепция потоковых данных. Хотя потоковые данные до сих пор иногда считаются передовой технологией, у них уже есть солидная история. Всё началось в 2002 году, когда исследователи Стэнфордского университета опубликовали статью «Модели и проблемы в системах потоковых данных». Однако лишь почти десятилетие спустя (в 2011 году) потоковые системы данных стали получать более широкую аудиторию, когда платформа Apache Kafka для хранения и обработки потоковых данных стала общедоступной. Остальное, как говорится, уже история. Сегодня обработка потоковых данных считается не роскошью, а необходимостью.
Microsoft осознаёт растущую потребность в обработке данных «как только они поступают». Поэтому Microsoft Fabric не разочаровывает в этом отношении, поскольку Real-time Intelligence лежит в основе всей платформы и предлагает целый спектр возможностей для эффективной обработки потоковых данных.
Прежде чем углубляться в объяснение каждого компонента Real-time Intelligence, давайте сделаем шаг назад и рассмотрим более инструментально-независимый подход к потоковой обработке в целом.
Что такое потоковая обработка?
Если вы введёте фразу из заголовка раздела в поиск Google, вы получите более 100 000 результатов! Поэтому я поделюсь иллюстрацией, которая отражает наше понимание потоковой обработки.

Давайте теперь рассмотрим типичные варианты использования потоковой обработки:
- Обнаружение мошенничества
- Торги акциями в реальном времени
- Активность клиентов
- Мониторинг журналов — устранение неполадок в системах, устройствах и т. д.
- Управление информацией о безопасности и событиями — анализ журналов и данных о событиях в реальном времени для мониторинга и обнаружения угроз
- Складской инвентарь
- Сопоставление поездок
- Машинное обучение и предиктивная аналитика
Как вы, возможно, заметили, потоковые данные стали неотъемлемой частью множества реальных сценариев и считаются значительно более эффективными, чем традиционная пакетная обработка для вышеупомянутых случаев использования.
Давайте теперь рассмотрим, как выполняется потоковая обработка данных в Microsoft Fabric и какие инструменты для этого имеются в нашем распоряжении.
На следующем рисунке показан общий обзор всех компонентов Real-time Intelligence в Microsoft Fabric:

Концентратор в реальном времени
Начнём с создания концентратора реального времени. Каждый арендатор Microsoft Fabric автоматически подготавливает концентратор реального времени. Это центральная точка для всех данных, находящихся в движении, во всей организации. Как и в OneLake, для каждого арендатора может быть только один концентратор реального времени — это означает, что вы не можете подготовить или создать несколько концентраторов реального времени.
Основная цель Real-Time Hub — обеспечить быстрый и простой поиск, прием, управление и использование потоковых данных из широкого спектра источников. На следующем рисунке представлен обзор всех потоков данных в Real-Time Hub в Microsoft Fabric:

Давайте теперь рассмотрим все доступные опции в Real-Time Hub.
- На вкладке «Все потоки данных» отображаются все доступные вам потоки и таблицы. Потоки представляют собой выходные данные потоков событий Fabric, а таблицы — баз данных KQL. Мы подробнее рассмотрим как потоки событий, так и базы данных KQL в следующих разделах.
- На вкладке «Мои потоки данных» отображаются все потоки, которые вы перенесли в Microsoft Fabric в «Мое рабочее пространство».
- Вкладка «Источники данных» играет ключевую роль в передаче данных в Fabric, как извне, так и изнутри. На вкладке «Источники данных» вы можете выбрать один из множества готовых коннекторов, таких как Kafka, потоки CDC для различных систем баз данных, внешние облачные решения, такие как AWS и GCP, и многое другое.
- Вкладка «Источники Microsoft» отфильтровывает предыдущий набор источников, оставляя только источники данных Microsoft.
- На вкладке «События Fabric» отображается список системных событий, созданных в Microsoft Fabric, к которым вы можете получить доступ. Здесь вы можете выбрать между событиями заданий, событиями OneLake и событиями элементов рабочей области. Давайте подробнее рассмотрим каждый из этих трёх вариантов:
- События заданий — это события, вызванные изменениями статуса в действиях монитора Fabric, такими как создание, успешное или неудавшееся задание.
- События OneLake представляют собой события, возникающие в результате действий с файлами и папками в OneLake, например, создание, удаление или переименование файла.
- События элементов рабочего пространства возникают в результате действий над элементами рабочего пространства, таких как создание, удаление или переименование элемента.
- Вкладка «События Azure» отображает список системных событий, созданных в хранилище BLOB-объектов Azure.
Концентратор Real-Time предоставляет различные коннекторы для загрузки данных в Microsoft Fabric. Он также позволяет создавать потоки данных для всех поддерживаемых источников. После создания потока вы можете обрабатывать его, анализировать и выполнять соответствующие действия.
- Обработка потока позволяет применять множество преобразований, таких как агрегация, фильтрация, объединение и многие другие. Цель — преобразовать данные перед отправкой вывода в поддерживаемые пункты назначения.
- Анализ потока позволяет добавить базу данных KQL в качестве назначения потока, а затем открыть базу данных KQL и выполнить запросы к ней.
- Действия на основе потоков предполагают установку оповещений на основе условий и указание действий, которые необходимо предпринять при выполнении определенных условий.
Eventstreams
Если вы специалист по работе с данными, не требующий программирования или требующий минимального программирования, и вам необходимо обрабатывать потоковые данные, вам понравится Eventstreams. Вкратце, Eventstream позволяет подключаться к различным источникам данных, которые мы рассмотрели в предыдущем разделе, при необходимости применять различные этапы преобразования данных и, наконец, выводить результаты в один или несколько пунктов назначения. На следующем рисунке показана стандартная схема загрузки потоковых данных в три разных пункта назначения — Eventhouse, Lakehouse и Activator:

В настройках Eventstream вы можете настроить срок хранения входящих данных. По умолчанию данные хранятся один день, а события автоматически удаляются по истечении срока хранения.
Кроме того, вы можете настроить пропускную способность для входящих и исходящих событий. Доступны три варианта:
- Низкая : < 10 МБ/с
- Средний : 10-100 МБ/с
- Высокая : > 100 МБ/с
Eventhouse и база данных KQL
В предыдущем разделе вы узнали, как подключаться к различным источникам потоковых данных, при необходимости преобразовывать данные и загружать их в конечное место назначения. Как вы, возможно, заметили, одним из доступных мест назначения является Eventhouse. В этом разделе мы рассмотрим элементы Microsoft Fabric, используемые для хранения данных в рабочей нагрузке Real-Time Intelligence.
Eventhouse
Сначала мы рассмотрим элемент Eventhouse. Eventhouse — это не что иное, как контейнер для баз данных KQL. Сам Eventhouse не хранит никаких данных — он просто предоставляет инфраструктуру в рабочей области Fabric для работы с потоковыми данными. На следующем рисунке показана страница обзора системы Eventhouse:

Преимущество страницы «Обзор системы» заключается в том, что она предоставляет всю ключевую информацию одним взглядом. Таким образом, вы сразу можете оценить текущее состояние центра событий, использование хранилища OneLake с дальнейшей детализацией по отдельным уровням базы данных KQL, использование вычислительных ресурсов, наиболее активные базы данных и пользователи, а также последние события.
Если мы перейдем на страницу «Базы данных», мы сможем увидеть общий обзор баз данных KQL, которые являются частью существующего Eventhouse, как показано ниже:

Вы можете создать несколько центров событий в одном рабочем пространстве Fabric. Кроме того, один центр событий может содержать одну или несколько баз данных KQL:

Завершим рассказ о Eventhouse, объяснив концепцию минимального потребления . Eventhouse изначально оптимизирован для автоматической приостановки сервисов, когда они не используются. Поэтому при повторной активации сервисов может потребоваться некоторое время для полного восстановления его доступности. Однако существуют определённые бизнес-сценарии, когда такая задержка неприемлема. В таких сценариях обязательно настройте функцию минимального потребления. Настроив минимальное потребление, вы сами определяете минимальный уровень, который затем будет доступен для баз данных KQL в Eventhouse.
База данных KQL
Теперь, когда вы узнали о контейнере Eventhouse, давайте сосредоточимся на изучении основного элемента для хранения аналитических данных в реальном времени — базы данных KQL.
Давайте сделаем шаг назад и сначала объясним название этого термина. Хотя большинство специалистов по работе с данными хотя бы слышали о SQL (языке структурированных запросов), я почти уверен, что KQL гораздо более загадочен, чем его «структурированный» родственник.
Вы, возможно, справедливо предположили, что QL в аббревиатуре означает Query Language (язык запросов). Но что означает эта буква K? Это сокращение от Kusto. Я вас понял, я вас понял: что теперь называется Kusto?! Хотя городская легенда гласит, что язык был назван в честь знаменитого полимата и океанографа Жака-Ива Кусто (его фамилия произносится как «Кусто»), мне не удалось найти официального подтверждения этой истории от Microsoft. Точно известно, что это было внутреннее название проекта для Log Analytics Query Language.
Раз уж мы заговорили об истории, давайте поделимся ещё несколькими историческими уроками. Если вы когда-либо работали с Azure Data Explorer (ADX), вам повезло. База данных KQL в Microsoft Fabric — официальный преемник ADX. Подобно многим другим службам данных Azure, которые были переработаны и интегрированы в SaaS-ориентированную архитектуру Fabric, ADX предоставил платформу для хранения и запроса аналитических данных в режиме реального времени для баз данных KQL. Механизм и основные возможности базы данных KQL такие же, как и в Azure Data Explorer, — ключевое отличие заключается в способе управления: Azure Data Explorer представляет собой PaaS-решение (платформа как услуга), тогда как база данных KQL — SaaS-решение (программное обеспечение как услуга).
Хотя в базе данных KQL можно хранить любые данные (неструктурированные, полуструктурированные и структурированные), её основное предназначение — обработка телеметрии, журналов, событий, трассировок и данных временных рядов. В основе движка лежат оптимизированные форматы хранения, автоматическое индексирование и секционирование, а также расширенная статистика данных для эффективного планирования запросов.
Давайте теперь рассмотрим, как использовать базу данных KQL в Microsoft Fabric для хранения и запроса аналитических данных в реальном времени. Создание базы данных максимально просто. На следующем рисунке показан двухэтапный процесс создания базы данных KQL в Fabric:

- Нажмите на знак «+» рядом с базами данных KQL.
- Укажите имя базы данных и выберите её тип. Типом может быть новая база данных по умолчанию или база данных-ярлык. База данных-ярлык — это ссылка на другую базу данных, которая может быть либо другой базой данных KQL в Real-Time Intelligence в Microsoft Fabric, либо базой данных Azure Data Explorer.
Не путайте концепцию сокращенных ссылок OneLake с концепцией сокращенного типа базы данных в Real-Time Intelligence! В то время как последний просто ссылается на всю базу данных KQL/Azure Data Explorer, сокращенные ссылки OneLake позволяют использовать данные, хранящиеся в таблицах Delta, в других рабочих нагрузках OneLake, таких как озёрные хранилища и/или склады, а также во внешних источниках данных (ADLS Gen2, Amazon S3, Dataverse, Google Cloud Storage и т.д.). Доступ к этим данным из баз данных KQL можно получить с помощью функции external_table().
Давайте кратко рассмотрим ключевые функции базы данных KQL с точки зрения пользовательского интерфейса. На рисунке ниже представлены основные моменты, представляющие интерес:

- Таблицы – отображает все таблицы в базе данных.
- Ярлыки – показывает таблицы, созданные как ярлыки OneLake.
- Материализованные представления – материализованное представление представляет собой запрос агрегации к исходной таблице или другому материализованному представлению. Оно состоит из одного оператора суммирования.
- Функции – это пользовательские функции, которые хранятся и управляются на уровне базы данных, подобно таблицам. Эти функции создаются с помощью команды .create function.
- Потоки данных – все потоки, имеющие отношение к выбранной базе данных KQL.
- Отслеживание активности данных – показывает активность в базе данных за выбранный период времени.
- Таблицы/Предварительный просмотр данных – позволяет переключаться между двумя различными представлениями. В представлении «Таблицы» отображается общий обзор таблиц базы данных, а в представлении «Предварительный просмотр данных» – первые 100 записей выбранной таблицы.
Запрос и визуализация данных в режиме реального времени
Теперь, когда вы научились хранить аналитические данные в реальном времени в Microsoft Fabric, пришло время взяться за дело и извлечь из этих данных ценную бизнес-информацию. В этом разделе я расскажу о различных способах извлечения полезной информации из данных, хранящихся в базе данных KQL.
Поэтому в этом разделе я представлю общие функции KQL для извлечения данных и рассмотрю панели мониторинга в реальном времени для визуализации данных.
набор запросов KQL
Набор запросов KQL — это элемент структуры, используемый для выполнения запросов, а также просмотра и настройки результатов из различных источников данных. Как только вы создаёте новую базу данных KQL, набор запросов KQL будет предоставлен автоматически. Это набор запросов KQL по умолчанию, который автоматически подключается к базе данных KQL, в которой он находится. Набор запросов KQL по умолчанию не допускает множественных подключений.
С другой стороны, при создании пользовательского элемента набора запросов KQL вы можете подключить его к нескольким источникам данных, как показано на следующем рисунке:

Давайте теперь рассмотрим основные элементы KQL и рассмотрим некоторые наиболее часто используемые операторы и функции. KQL — довольно простой, но мощный язык. В некоторой степени он очень похож на SQL, особенно в плане использования сущностей схемы, организованных в иерархии, таких как базы данных, таблицы и столбцы.
Наиболее распространённый тип оператора KQL-запроса — это оператор табличного выражения . Это означает, что как входные, так и выходные данные запроса состоят из таблиц или табличных наборов данных. Операторы в табличном операторе обозначаются символом «|» (вертикальная черта). Данные передаются (поступают по конвейеру) от одного оператора к другому, как показано в следующем фрагменте кода:
MyTable | где StartTime между (datetime(2024-11-01) .. datetime(2024-12-01)) | где State == «Texas» | count
Передача данных является последовательной — данные передаются от одного оператора к другому — это означает, что порядок операторов запроса важен и может влиять как на выходные результаты, так и на производительность.
В приведенном выше примере кода данные в MyTable сначала фильтруются по столбцу StartTime, затем фильтруются по столбцу State, и, наконец, запрос возвращает таблицу, содержащую один столбец и одну строку, отображающую количество отфильтрованных строк.
В связи с этим возникает справедливый вопрос: а что, если я уже знаю SQL? Нужно ли мне изучать ещё один язык только ради запросов к аналитическим данным в режиме реального времени? Ответ, как обычно, зависит от ситуации.
К счастью, у меня есть хорошие и замечательные новости, которыми я хочу поделиться!
Хорошая новость: вы МОЖЕТЕ писать SQL-запросы к данным, хранящимся в базе данных KQL. Но тот факт, что вы можете что-то сделать, не означает, что вы должны это делать… Используя только SQL-запросы, вы упускаете суть и ограничиваете себя в использовании множества специфичных для KQL функций, разработанных для обработки аналитических запросов в реальном времени наиболее эффективным способом.
Отличная новость: используя оператор Explain , вы можете «попросить» Kusto перевести ваш оператор SQL в эквивалентный оператор KQL, как показано на следующем рисунке:

В следующих примерах мы выполним запросы к образцу набора данных Weather, содержащего данные о штормах и ущербе, причиненном стихией в США. Начнём с простого, а затем перейдём к более сложным запросам. В первом примере мы подсчитаем количество записей в таблице Weather:
//Подсчет записей Погода | количество
Хотите получить только подмножество записей? Можно использовать оператор take или limit:
//Пример данных Погода | дубль 10
Имейте в виду, что оператор take не вернёт первые n записей, если только данные не отсортированы в определённом порядке. Обычно оператор take возвращает любое количество n записей из таблицы.
На следующем шаге мы хотим расширить этот запрос и вернуть не только подмножество строк, но и подмножество столбцов:
//Выборка данных из подмножества столбцов Weather | take 10 | project State, EventType, DamageProperty
Оператор project эквивалентен оператору SELECT в SQL. Он определяет, какие столбцы следует включить в результирующий набор.
В следующем примере мы создаём вычисляемый столбец Duration, представляющий собой интервал между значениями EndTime и StartTime. Кроме того, мы хотим отобразить только первые 10 записей, отсортированных по значению DamageProperty в порядке убывания:
//Создать вычисляемые столбцы Погода | где State == 'NEW YORK' и EventType == 'Зимняя погода' | топ-10 по DamageProperty desc | проект StartTime, EndTime, Duration = EndTime — StartTime, DamageProperty
Сейчас самое время представить оператор суммирования . Этот оператор создаёт таблицу, агрегирующую содержимое входной таблицы. Таким образом, следующий оператор выведет общее количество записей для каждого штата, включая только первые 5 штатов:
//Используйте оператор суммирования Weather | summarise TotalRecords = count() по штатам | top 5 по TotalRecords
Давайте расширим предыдущий код и визуализируем данные непосредственно в наборе результатов. Я добавлю ещё одну строку KQL-кода для отображения результатов в виде столбчатой диаграммы:

Как вы можете заметить, диаграмму можно дополнительно настраивать с помощью панели визуального форматирования с правой стороны, что обеспечивает еще большую гибкость при визуализации данных, хранящихся в базе данных KQL.
Это были лишь базовые примеры использования языка KQL для извлечения данных из баз данных Eventhouse и KQL. Уверяю вас, KQL не подведет и в более сложных случаях, когда вам потребуется обрабатывать и извлекать аналитические данные в режиме реального времени.
Я понимаю, что SQL — это «язык общения» многих специалистов по работе с данными. И хотя вы можете использовать SQL для извлечения данных из базы данных KQL, я настоятельно рекомендую вам воздержаться от этого. В качестве краткого справочника я предлагаю вам « шпаргалку по переходу с SQL на KQL », которая поможет вам быстро перейти с SQL на KQL.
Кроме того, мой друг и коллега, MVP Брайан Бёнк, опубликовал и поддерживает великолепное справочное руководство по языку KQL. Обязательно ознакомьтесь с ним, если работаете с KQL.
Панели управления в реальном времени
Хотя наборы запросов KQL представляют собой мощный инструмент для исследования и выполнения запросов к данным, хранящимся в Eventhouses и базах данных KQL, их возможности визуализации довольно ограничены. Да, вы можете визуализировать результаты в представлении запроса, как вы видели в одном из предыдущих примеров, но это скорее визуализация «первой помощи», которая не понравится вашим менеджерам и лицам, принимающим решения.
К счастью, в Real-Time Intelligence есть готовое решение, поддерживающее расширенные концепции и функции визуализации данных. Real-Time Dashboard — это элемент Fabric, позволяющий создавать интерактивные и визуально привлекательные решения для бизнес-отчётности.
Давайте сначала определим основные элементы панели мониторинга в реальном времени. Панель мониторинга состоит из одной или нескольких плиток, которые могут быть структурированы и организованы в страницы, где каждая плитка заполняется базовым KQL-запросом.
В качестве первого шага в процессе создания панелей мониторинга в реальном времени необходимо включить этот параметр на портале администратора вашего клиента Fabric:

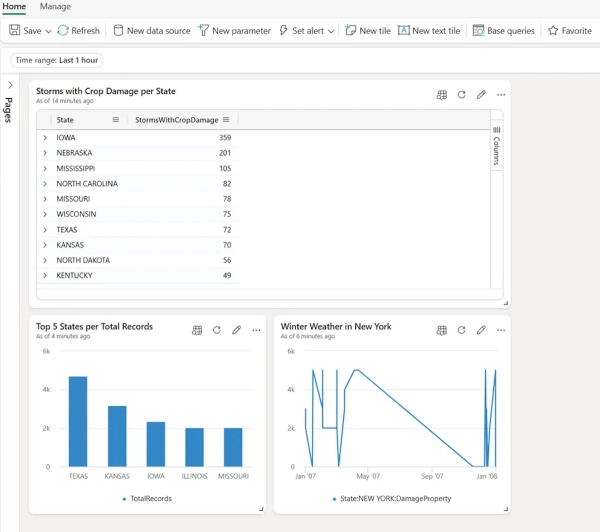
Далее необходимо создать новый элемент панели мониторинга в реальном времени в рабочей области Fabric. Далее подключимся к нашему набору данных Weather и настроим первую плитку панели мониторинга. Мы выполним один из запросов из предыдущего раздела, чтобы получить 10 лучших штатов с помощью функции условного подсчёта. На рисунке ниже показана панель настроек плитки с многочисленными опциями для настройки:

- KQL-запрос для заполнения плитки
- Визуальное представление данных
- Панель визуального форматирования с возможностью задать имя и описание плитки
- Раскрывающееся меню типа визуализации для выбора желаемого типа визуализации (в нашем случае это табличное изображение)
Давайте добавим ещё две плитки на нашу панель управления. Я скопирую и вставлю два запроса, которые мы использовали ранее: первый извлечёт 5 лучших штатов по общему количеству записей, а второй отобразит изменение стоимости ущерба имуществу с течением времени для штата Нью-Йорк и для типа события, который соответствует зимней погоде.

Вы также можете добавить плитку непосредственно из набора запросов KQL на существующую панель управления, как показано ниже:

Теперь давайте рассмотрим различные возможности, доступные при работе с панелями мониторинга в реальном времени. В верхней части ленты вы найдёте опции для добавления нового источника данных, настройки нового параметра и добавления базовых запросов. Однако по-настоящему мощными панелями мониторинга в реальном времени является возможность настройки оповещений. В зависимости от выполнения условий, заданных в оповещении, вы можете инициировать определённое действие, например, отправку электронного письма или сообщения в Microsoft Teams. Оповещение создаётся с помощью элемента «Активатор».

Визуализируйте данные с помощью Power BI
Power BI — это зрелый и широко используемый инструмент для создания надежных, масштабируемых и интерактивных решений для бизнес-отчетности. В этом разделе мы подробно рассмотрим взаимодействие Power BI с рабочей нагрузкой Real-Time Intelligence в Microsoft Fabric.
Создать отчёт Power BI на основе данных, хранящихся в базе данных KQL, проще простого. Вы можете создать отчёт Power BI непосредственно из набора запросов KQL, как показано ниже:

Каждый запрос в наборе запросов KQL представляет собой таблицу в семантической модели Power BI. На основе этой таблицы вы можете создавать визуализации и использовать все существующие функции Power BI для создания эффективных и визуально привлекательных отчётов.
Очевидно, вы по-прежнему можете использовать «обычный» рабочий процесс Power BI, который предполагает подключение Power BI Desktop к базе данных KQL в качестве источника данных. В этом случае вам необходимо открыть концентратор данных OneLake и выбрать базы данных KQL в качестве источника данных:

Как и для источников данных на основе SQL, вы можете выбрать режимы хранения данных аналитики в реальном времени: импорт и DirectQuery. Режим импорта создаёт локальную копию данных в базе данных Power BI, тогда как DirectQuery позволяет выполнять запросы к базе данных KQL в режиме, близком к реальному времени.
Активатор
Activator — одна из самых инновационных функций во всём мире Microsoft Fabric. Я подробно расскажу об Activator в отдельной статье. Здесь же я хочу лишь представить этот сервис и кратко осветить его основные характеристики.
Activator — это решение без написания кода для автоматического выполнения действий при выполнении условий в базовых данных. Activator можно использовать вместе с Eventstreams, панелями мониторинга в реальном времени и отчётами Power BI. Как только данные достигают определённого порогового значения, Activator автоматически запускает указанное действие, например, отправку электронного письма или сообщения Microsoft Teams или даже запуск потоков Power Automate. Я подробнее рассмотрю все эти сценарии в отдельной статье, где также приведу несколько практических примеров реализации элемента Activator.
Заключение
Real-Time Intelligence — то, что изначально было частью «опыта Synapse» в Microsoft Fabric, теперь представляет собой отдельную, специализированную рабочую нагрузку. Это многое говорит нам о видении и планах Microsoft в отношении Real-Time Intelligence!
Не забывайте: изначально аналитика в реальном времени входила в состав Synapse вместе с функциями Data Engineering, Data Warehousing и Data Science. Однако Microsoft посчитала, что обработка потоковых данных заслуживает отдельной рабочей нагрузки в Microsoft Fabric, что абсолютно логично, учитывая растущую потребность в обработке динамических данных и предоставлении аналитической информации на основе этих данных сразу после их получения. В этом смысле Microsoft Fabric предоставляет целый набор мощных сервисов, являясь инструментами нового поколения для обработки, анализа и обработки данных по мере их поступления.
Я совершенно уверен, что рабочая нагрузка по анализу данных в реальном времени будет становиться все более значимой в будущем, учитывая эволюцию источников данных и увеличивающиеся темпы их генерации.
Спасибо за прочтение!
Источник: towardsdatascience.com

























