Чтобы понять, действительно ли ваше агентское решение лучше.
Делиться
: преобразование агентного решения в непрерывную оценку 1")
Вкратце
- В здравоохранении агентные системы искусственного интеллекта часто выдают бинарные решения, такие как наличие или отсутствие заболевания, которые сами по себе не могут обеспечить значимый показатель AUC.
- AUC по-прежнему является стандартным способом сравнения моделей оценки риска и обнаружения в медицине, и для его использования требуются непрерывные показатели, позволяющие ранжировать пациентов по степени риска.
- В этой статье описаны несколько практических стратегий преобразования результатов работы агентов в непрерывные оценки, чтобы сравнения на основе AUC с традиционными моделями оставались достоверными и справедливыми.
Разрыв между агентом и площадью под кривой
Системы агентного искусственного интеллекта становятся все более распространенными, поскольку они снижают барьер для внедрения решений в области ИИ. Они достигают этого за счет использования базовых моделей, благодаря чему не всегда требуется тратить ресурсы на обучение пользовательской модели с нуля или на многократную тонкую настройку.
Я заметил, что примерно 20–25% докладов на NeurIPS 2025 были посвящены агентным решениям. Параллельно с этим растет популярность агентов для медицинских приложений. К таким системам относятся конвейеры обработки данных на основе LLM, агенты с расширенными возможностями поиска и многошаговые системы принятия решений. Они могут синтезировать разнородные данные, пошагово рассуждать и выдавать контекстные рекомендации или решения.
Большинство этих систем созданы для ответа на вопросы типа «Болен ли этот пациент этим заболеванием?» или «Следует ли назначить этот тест?», а не на вопрос «Какова вероятность того, что этот пациент болен этим заболеванием?». Другими словами, они, как правило, приводят к сложным решениям и объяснениям, а не к точно рассчитанным вероятностям.
В отличие от этого, традиционные медицинские модели оценки риска и выявления заболеваний обычно оцениваются с помощью площади под кривой рабочей характеристики приемника (AUC). AUC широко используется в клинической прогностической работе и является стандартным показателем для сравнения моделей во многих исследованиях, связанных с визуализацией, оценкой риска и скринингом.
Это создает пробел. Если наши новые модели являются агентными и ориентированы на принятие решений, но наши стандарты оценки основаны на вероятности, нам нужны методы, которые связывают эти два подхода. Остальная часть этой статьи посвящена тому, что на самом деле нужно AUC, почему бинарных выходных данных недостаточно и как получить непрерывные оценки из агентных моделей, чтобы AUC оставался пригодным для использования.
Почему AUC важен и почему бинарные выходные данные дают сбой
В медицинских приложениях AUC часто считается эталонным показателем, поскольку он лучше, чем простая точность, справляется с дисбалансом между случаями и контрольной группой, особенно в наборах данных, отражающих реальную распространенность заболевания.
Точность может быть обманчивым показателем, когда распространенность заболевания низка. Например, распространенность рака молочной железы в популяции, проходящей скрининг, составляет примерно 5 случаев на 1000. Модель, которая предсказывает «отсутствие рака» для каждого случая, все равно будет обладать очень высокой точностью, но частота ложноотрицательных результатов будет неприемлемо высокой. В реальных клинических условиях это явно плохая модель, несмотря на ее точность.
AUC измеряет, насколько хорошо модель разделяет положительные и отрицательные случаи. Для этого используется непрерывная оценка для каждого отдельного случая, и определяется, насколько хорошо эти оценки ранжируют положительные случаи выше отрицательных. Именно такой подход, основанный на ранжировании, делает AUC полезным даже при сильном дисбалансе классов.
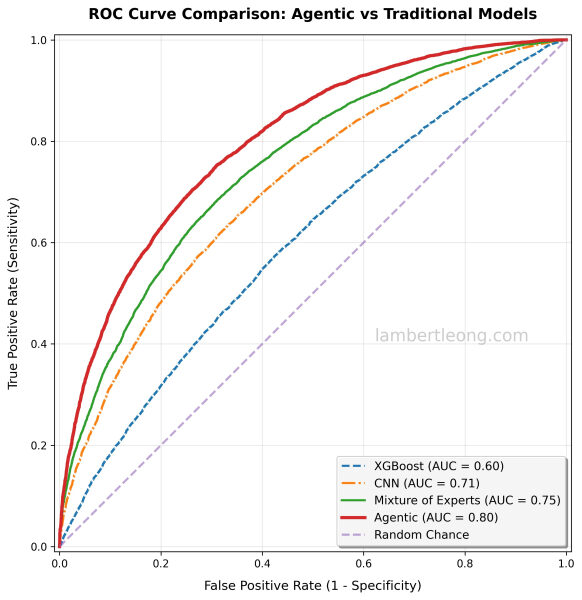
Хотя на конференции NeurIPS я заметил множество инновационных работ на стыке агентных вычислений и здравоохранения, я не увидел много статей, в которых сообщалось бы о показателе AUC. Я также не видел много работ, в которых сравнивался бы новый агентный подход с существующими или устоявшимися моделями машинного обучения или глубокого обучения с использованием стандартных метрик. Без этого сложно откалибровать и понять, насколько лучше эти агентные решения на самом деле, если вообще лучше.
Большинство современных результатов работы агентных систем не позволяют естественным образом получить значения AUC. Цель этой статьи — предложить методы получения AUC для агентных систем, чтобы мы могли начать конкретное обсуждение повышения производительности по сравнению с предыдущими и существующими решениями.
Как вычисляется AUC
Чтобы полностью понять существующую проблему и оценить попытки ее решения, следует рассмотреть, как рассчитываются показатели AUC.
Позволять
- Пусть y ∈ {0, 1} — истинная метка.
- Пусть s ∈ ℝ — оценка модели для каждого отдельного пользователя.
Кривая ROC строится путем сканирования порогового значения t по всему диапазону значений и вычисления
- Чувствительность на каждом пороговом значении
- Специфичность на каждом пороговом значении
Значение AUC можно интерпретировать следующим образом:
Вероятность того, что случайно выбранный положительный случай имеет более высокий балл, чем случайно выбранный отрицательный случай.
Такая интерпретация имеет смысл только в том случае, если оценки содержат достаточно детализированные данные, чтобы обеспечить ранжирование отдельных лиц. На практике это означает, что нам нужны непрерывные или, по крайней мере, точно упорядоченные значения, а не только нули и единицы.
Почему бинарные результаты работы агентов нарушают AUC
Агентные системы часто выдают только бинарное решение. Например:
- «Болезнь» соотнесена с 1
- «Отсутствие заболевания» соответствует значению 0.
Если это единственно возможные результаты, то существует всего два уникальных значения. При изменении пороговых значений в этом наборе кривая ROC сужается максимум до одной нетривиальной точки плюс тривиальные конечные точки. Нет ни богатого набора пороговых значений, ни осмысленного ранжирования.
В этом случае значение AUC становится либо неопределенным, либо вырожденным. Кроме того, его нельзя корректно сравнивать со значениями AUC, полученными с помощью традиционных моделей, которые выдают непрерывные вероятности.
: преобразование агентного решения в непрерывную оценку 2")
Для оценки эффективности агентных решений с использованием AUC необходимо создать непрерывную шкалу, отражающую степень уверенности агента в положительности того или иного случая.
Что нам нужно
Для вычисления AUC для агентной системы нам необходима непрерывная оценка, отражающая лежащую в её основе оценку риска, уверенность или ранжирование. Оценка не обязательно должна быть идеально откалиброванной вероятностью. Она должна лишь обеспечивать упорядочение по пациентам, соответствующее внутреннему представлению агента о риске.
Ниже приведён список практических стратегий для преобразования результатов деятельности субъектов в подобные оценки.
Методы получения непрерывных оценок из агентных систем
- Извлечь вероятности из логарифмов внутренней модели.
- Попросите агента вывести явную вероятность.
- Используйте метод Монте-Карло с повторными выборками для оценки вероятности.
- Преобразуйте показатели сходства результатов поиска в показатели риска.
- Обучите калибровочную модель на основе выходных данных агента.
- Изменяйте настраиваемый пороговый уровень или конфигурацию внутри агента, чтобы приблизительно построить ROC-кривую.
Таблица сравнения
| Метод | Плюсы | Минусы |
|---|---|---|
| Логарифмические вероятности | Непрерывный, стабильный сигнал, соответствующий логике и ранжированию модели. | Требуется доступ к логам и может быть чувствителен к формату подсказки. |
| Явный вывод вероятности | Простой, интуитивно понятный и легко понятный для врачей и экспертов. | Качество калибровки зависит от подсказок и поведения модели. |
| Метод Монте-Карло | Позволяет зафиксировать истинную неопределенность принятия решений агентом без доступа к внутренним ресурсам. | Это более дорогостоящий с вычислительной точки зрения метод, требующий нескольких запусков на одного пациента. |
| Сходство при поиске | Идеально подходит для систем, основанных на поиске информации, и прост в вычислении. | Может не в полной мере отражать логику принятия решений на последующих этапах или общую аргументацию. |
| Модель калибровки | Преобразует структурированные или категориальные выходные данные в сглаженные показатели риска и может улучшить калибровку. | Требуется наличие размеченных данных и добавление вторичной модели в конвейер обработки данных. |
| Снятие порога | Работает даже тогда, когда агент предоставляет только бинарные выходные данные и настраиваемый параметр. | Получает приблизительное значение AUC, которое зависит от того, как параметр влияет на принимаемые решения. |
В следующем разделе каждый метод будет описан более подробно, включая объяснение того, почему он работает, когда он наиболее уместен и какие ограничения следует учитывать.
Источник: towardsdatascience.com