воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Мы представляем Afrimed-QA — набор контекстно релевантных наборов данных для оценки эффективности программ обучения гуманитарным и социальным наукам в решении задач по ответам на вопросы о здоровье в Африке, разработанный в партнерстве с организациями по всей Африке.
Быстрые ссылки
- Бумага
- Эталонные наборы данных
- Код оценки AfriMed-QA
- Делиться
Крупные языковые модели (КГМ) продемонстрировали потенциал для ответа на медицинские вопросы и вопросы, касающиеся здоровья, в различных тестах, охватывающих разные форматы и источники, такие как вопросы с множественным выбором и краткие ответы на экзаменах (например, USMLE MedQA), составление резюме и ведение клинических записей, и многое другое. Особенно в условиях ограниченных ресурсов КГМ могут служить ценными инструментами поддержки принятия решений, повышая точность и доступность клинической диагностики, а также обеспечивая многоязычную поддержку принятия клинических решений и обучение в области здравоохранения, что особенно ценно на уровне сообщества.
Несмотря на их успех на существующих медицинских эталонных наборах данных, остается неясным, насколько эти модели обобщаемы на задачи, связанные с изменением распределения типов заболеваний, контекстными различиями симптомов или вариациями языка и лингвистики, даже в рамках английского языка. Кроме того, локализованный культурный контекст и региональные медицинские знания важны для моделей, используемых за пределами традиционных западных условий. Однако без разнообразных эталонных наборов данных, отражающих широкий спектр реальных условий, невозможно обучать или оценивать модели в этих условиях, что подчеркивает необходимость в более разнообразных эталонных наборах данных.
Для решения этой проблемы мы представляем AfriMed-QA — эталонный набор данных вопросов и ответов, объединяющий вопросы потребительского типа и экзамены медицинского факультета из 60 медицинских школ в 16 странах Африки. Мы разработали этот набор данных в сотрудничестве с многочисленными партнерами, включая Intron health, Sisonkebiotik, Университет Кейп-Коста, Федерацию ассоциаций африканских студентов-медиков и BioRAMP, которые вместе образуют консорциум AfriMed-QA, а также при поддержке PATH/Фонда Гейтса. Мы оценили ответы студентов-медиков на этих наборах данных, сравнив их с ответами экспертов и оценив их в соответствии с предпочтениями людей. Методы, используемые в этом проекте, могут быть масштабированы для других регионов, где оцифрованные эталонные наборы данных в настоящее время могут быть недоступны.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
AfriMed-QA был представлен на конференции ACL 2025, где получил награду за лучшую работу, оказывающую социально значимую поддержку. Недавно этот набор данных был использован для обучения MedGemma, нашей новейшей открытой модели для понимания мультимодального медицинского текста и изображений. Наборы данных AfriMed-QA и код оценки LLM являются открытыми и доступны для использования сообществом.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Набор данных AfriMed-QA
Набор данных AfriMed-QA — это первый крупномасштабный панафриканский набор данных вопросов и ответов по различным медицинским специальностям, предназначенный для оценки и разработки справедливых и эффективных программ обучения на уровне средней школы (LLM) для африканского здравоохранения. Набор данных включает около 15 000 клинически разнообразных вопросов и ответов на английском языке, более 4000 вопросов с множественным выбором (MCQ) с ответами от экспертов, более 1200 вопросов с открытым ответом (SAQ) с развернутыми ответами и 10 000 вопросов от потребителей (CQ). Набор данных разработан для тщательной оценки эффективности программ обучения на уровне средней школы с точки зрения правильности и учета географических особенностей. Он был создан с помощью краудсорсинга 621 участником из более чем 60 медицинских школ в 12 странах, охватывающих 32 медицинские специальности, включая акушерство и гинекологию, нейрохирургию, внутреннюю медицину, неотложную медицину, медицинскую генетику, инфекционные заболевания и другие.

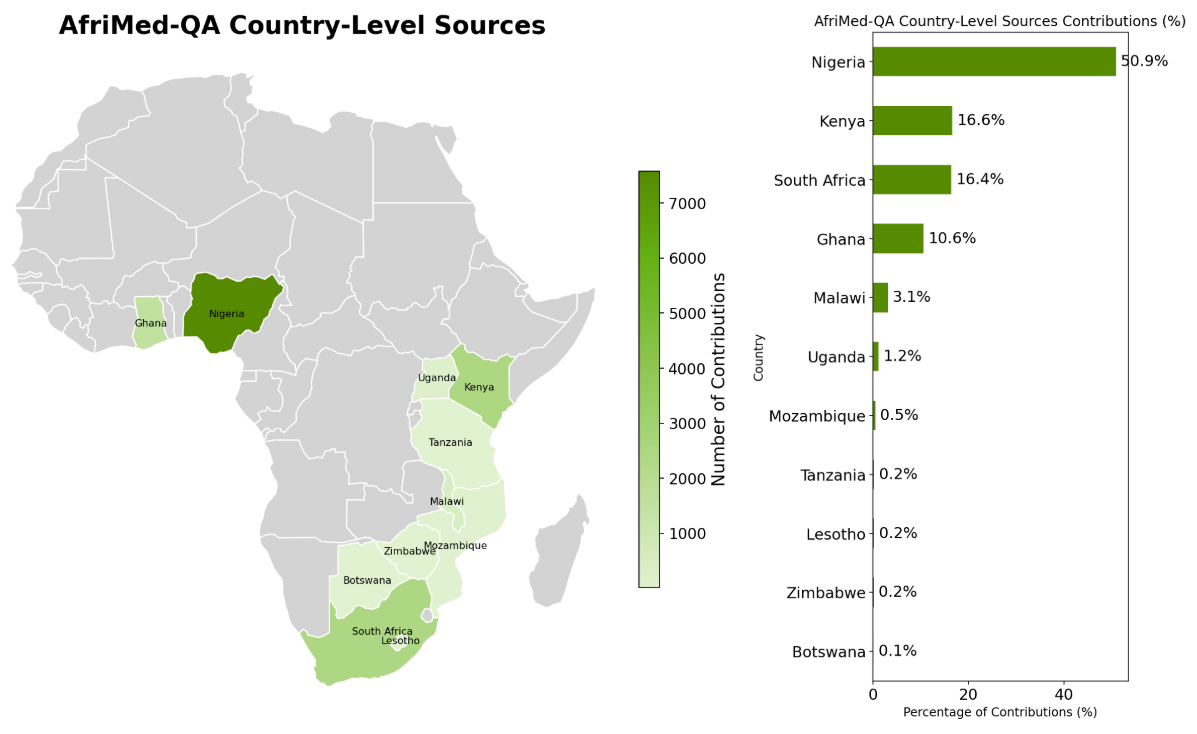
Страны, откуда были получены вопросы и ответы AfriMed-QA.
Для сбора этих данных мы адаптировали веб-платформу, ранее разработанную компанией Intron Health для массового сбора клинических данных о речи с акцентом и на нескольких языках по всей Африке. Мы разработали пользовательские интерфейсы для сбора данных по каждому типу вопросов, для проверки качества и для слепой оценки ответов на вопросы на многоязычные темы.

Обзор процесса обработки данных AfriMed-QA и оценки LLM. Вопросы с множественным выбором и вопросы с кратким ответом из медицинских школ были снабжены экспертной маркировкой. Для вопросов с кратким ответом, чтобы избежать разглашения потребителями собственной медицинской информации, что могло бы привести к потенциальному раскрытию данных, а также повторения типов вопросов, потребителям предлагался сценарий заболевания, и они отвечали вопросом, который бы задали на его основе. Сценарий и вопрос передавались эксперту LLM, и ответы LLM оценивались клиническими экспертами, а также потребителями.

В AfriMed-QA представлены медицинские специальности.
Оценка ответов LLM
Используя количественные и качественные подходы, мы оценили 30 языковых моделей общего и биомедицинского профиля, различающихся по размеру от небольших до крупных. Некоторые были открытыми, другие — закрытыми. Для вопросов с множественным выбором мы измеряли точность, сравнивая однобуквенный вариант ответа каждой языковой модели с эталонным ответом. Для вопросов с кратким ответом мы измеряли семантическое сходство и совпадение на уровне предложений, сравнивая сгенерированный ответ языковой модели с эталонным ответом.
Мы обнаружили, что базовая производительность более крупных моделей выше, чем у небольших моделей на AfriMed-QA. Эта тенденция может быть неблагоприятной для условий с ограниченными ресурсами, где предпочтительнее развертывание на устройствах или периферии с использованием небольших специализированных моделей.

Результаты работы моделей LLM на наборе данных AfriMed-QA (эксперименты по состоянию на май 2025 г.).
Мы также обнаружили, что базовые общие модели превосходят и лучше обобщают данные, чем биомедицинские модели аналогичного размера. Этот нелогичный результат может быть обусловлен ограничениями размера параметров открытых биомедицинских моделей в нашем исследовании, или же он может указывать на то, что специализированные линейные модели обучения переобучаются на специфических смещениях и нюансах данных, на которых они были доработаны. В любом случае, они, по-видимому, менее приспособлены к уникальным характеристикам набора данных AfriMed-QA.
Оценка ответов LLM человеком
Ответы LLM на фиксированный набор вопросов ( n = 3000; случайная выборка) были разосланы для оценки людьми на краудсорсинговой платформе Intron Health. Адаптируя оси оценки, описанные в нашей статье о MedLM, которые включали показатели неточности, упущения информации, признаков демографической предвзятости и степени вреда, мы собрали оценки людей в двух категориях:
- Врачи оценивали ответы на вопросы MCQ, SAQ и CQ опросника LLM, определяя, были ли ответы правильными и локализованными, присутствовали ли пропуски или галлюцинации, а также существовала ли потенциальная опасность.
- Немедицинские специалисты/потребители оценивали ответы CQ LLM, чтобы определить, были ли они релевантными, полезными и адаптированными к местным условиям.

Интерфейс, используемый для экспертной оценки ответов студентов магистратуры по гуманитарным наукам на вопросы AfriMed-QA.
Оценки выставлялись по 5-балльной шкале, отражающей степень соответствия критериям. «1» означает «Нет» или «полностью отсутствует», а «5» — «Да» или «абсолютно присутствует». Оценщики не знали источника ответа (название модели или человек), и каждому оценщику было предложено оценить ответы нескольких моделей в случайной последовательности.
Оценка ответов на клинические вопросы, предоставленных потребителями и врачами, показала предпочтение именно таким ответам: ответы, предоставленные врачами, неизменно оценивались как более полные, информативные и релевантные по сравнению с ответами, предоставленными врачами, и менее подверженные искажениям и упущениям. В соответствии с этим, ответы врачей на клинические вопросы также оценивались хуже с точки зрения упущения релевантной информации.

Оценка результатов клиническими экспертами и ответы студентов магистратуры в области медицины проводились вслепую. На графиках показаны средние оценки и доверительные интервалы по различным осям.
Создание открытой таблицы лидеров для удобного сравнения версий данных и версий LLM.
Мы разработали таблицу лидеров для удобной визуализации и сравнения производительности LLM. Пользователи могут сравнивать существующие модели или отправлять свои собственные модели и видеть, насколько хорошо они работают на наборе данных.

Таблица лидеров AfriMed-QA позволяет сравнивать различные модели по разным эталонным показателям.
На пути к многоязычному, мультимодальному набору данных
Мы понимаем, что медицина по своей природе многоязычна и мультимодальна, и в настоящее время работаем с консорциумом AfriMed-QA под руководством профессора Стивена Мура из Университета Кейп-Коста над расширением системы ответов на вопросы, помимо текстовых вопросов на английском языке, до других официальных и родных языков континента. Мы также работаем над включением мультимодальных (например, визуальных и аудио) наборов данных для ответов на вопросы.
Ограничения
Хотя это первый крупномасштабный, многопрофильный, собранный из местных источников панафриканский набор данных такого рода, он отнюдь не является полным. Более 50% вопросов с множественным выбором от экспертов поступили из Нигерии. Мы работаем над расширением представительства из других африканских регионов и стран Глобального Юга.
Хотя разработка набора данных еще продолжается, эта работа закладывает основу для получения разнообразных и репрезентативных эталонных наборов данных в области здравоохранения в странах, где могут отсутствовать оцифрованные и легкодоступные эталонные наборы данных.
LLM-ы для обеспечения качества в сфере здравоохранения в географически разнообразных регионах
Учитывая чувствительность результатов, связанных со здоровьем, крайне важно оценивать эффективность программ обучения на местном уровне (LLM) с точки зрения точности, контекстуальности и культурной релевантности. В различных условиях можно ожидать разнообразных изменений в распределении ресурсов, к которым LLM должны адаптироваться. К ним относятся распространенность заболеваний, культурный контекст, ресурсы и инфраструктура, типы и номенклатура лекарственных препаратов, различия в рекомендациях по скринингу и лечению, инфраструктура медицинских технологий, доступность, типы медицинской помощи и чувствительные характеристики. Хотя наши оценки ограничены, мы призываем другие исследовательские и медицинские организации к дальнейшим исследованиям в этой области, созданию наборов данных для оценки и оптимизации LLM для использования в их контексте посредством партнерства и учета местных особенностей.
Благодарности
Мы хотели бы выразить признательность невероятному консорциуму AfriMed-QA и соавторам. Тоби Олатунджи, Чарльз Нимо, Авраам Оводунни, Тассалла Абдуллахи, Эммануэль Айоделе, Мардхия Санни, Чинемелу Ака, Фолафунми Омофойе, Футсе Юэго, Тимоти Фаниран, Бонавентура Ф.П. Доссу, Мошуд Йекини, Йонас Кемп, Кэтрин Хеллер, Джуд Чидубем Омеке, Чиди Асузу, Наоме А. Этори, Аймеру Ндиайе, Ифеома Око, Эванс Доу Оканси, Венди Кинара, Майкл Бест, Ирфан Эсса, Стивен Эдвард Мур и Крис Фури. Мы также хотели бы поблагодарить Билала Матина, Мелиссу Майлз, Миру Эммануэль-Фабулу и Селесту Гонда из Фонда Гейтса/PATH Digital Square за поддержку нашей работы, а также всех, кто предоставил данные. Наконец, мы благодарим Мариан Кроак за ее лидерство и поддержку.
Источник: research.google