Наглядный и интуитивно понятный способ понять, как дерево решений усваивает свое первое правило
Делиться

В течение первых 5 дней этого «Рождественского календаря» по машинному обучению мы изучили 5 моделей (или алгоритмов), все из которых основаны на расстояниях (локальное евклидово расстояние или глобальное расстояние Махаланобиса).
Пришло время изменить подход, верно? Мы вернёмся к понятию расстояния позже.
Сегодня мы увидим нечто совершенно новое: деревья решений!

Введение в простой набор данных
Давайте используем простой набор данных, содержащий только одну непрерывную характеристику.
Как всегда, идея в том, что вы можете визуализировать результаты самостоятельно. А затем нужно подумать, как заставить компьютер это сделать.

Мы можем визуально предположить, что для первого разделения есть два возможных значения: одно около 5,5 и другое около 12.
Теперь вопрос в том, какой из них нам выбрать?
Именно это мы и собираемся выяснить: как определить значение для первого разделения с помощью реализации в Excel?
Определив значение для первого разделения, мы можем применить тот же процесс для следующих разделений.
Вот почему мы реализуем в Excel только первое разделение.
Алгоритмический принцип регрессоров дерева решений
Я написал статью, в которой описывается, как всегда различать три этапа машинного обучения для его эффективного изучения, и давайте применим этот принцип к регрессорам дерева решений.
Таким образом, впервые у нас есть «настоящая» модель машинного обучения с нетривиальными шагами для всех трех.
Что это за модель?
Модель здесь представляет собой набор правил для разбиения набора данных, и для каждой разбиения мы присваиваем значение. Какое именно? Среднее значение y всех наблюдений в одной группе.
Таким образом, в то время как k-NN прогнозирует с использованием среднего значения ближайших соседей (схожих наблюдений с точки зрения переменных-признаков), регрессор дерева решений прогнозирует с использованием среднего значения группы наблюдений (схожих с точки зрения переменной-признака).
Процесс подбора или обучения модели
Для дерева решений этот процесс также называется полным выращиванием дерева. В случае регрессора дерева решений листья будут содержать только одно наблюдение, поэтому среднеквадратическая ошибка (СКО) будет равна нулю.
Создание дерева заключается в рекурсивном разбиении входных данных на всё более мелкие фрагменты или регионы. Для каждого региона можно рассчитать прогноз.
В случае регрессии прогноз представляет собой среднее значение целевой переменной для региона.
На каждом этапе процесса построения алгоритм выбирает признак и значение разделения, которые максимизируют один критерий, а в случае регрессора это часто среднеквадратическая ошибка (MSE) между фактическим значением и прогнозом.
Настройка или обрезка модели
Для дерева решений общий термин настройки модели также называется обрезкой, поскольку ее можно рассматривать как удаление узлов и листьев с полностью выросшего дерева.
Это также эквивалентно утверждению, что процесс построения останавливается при достижении определённого критерия, например, максимальной глубины или минимального количества выборок в каждом листовом узле. Именно эти гиперпараметры можно оптимизировать с помощью процесса настройки.
Процесс вывода
После построения регрессора дерева решений его можно использовать для прогнозирования целевой переменной для новых входных экземпляров, применяя правила и проходя по дереву от корневого узла до конечного узла, соответствующего значениям входных признаков.
Прогнозируемое целевое значение для входного экземпляра представляет собой среднее значение целевых значений обучающих выборок, попадающих в один и тот же конечный узел.
Реализация в Excel первого разделения
Вот шаги, которым мы будем следовать:
- Перечислите все возможные разделения
- Для каждого разделения мы рассчитаем MSE (среднюю квадратическую ошибку).
- Мы выберем разделение, которое минимизирует среднеквадратичную ошибку (MSE) в качестве оптимального следующего разделения.
Все возможные варианты разделения
Сначала нам нужно перечислить все возможные разбиения, являющиеся средними значениями двух последовательных значений. Нет необходимости проверять больше значений.

Расчет MSE для каждого возможного разделения
Для начала мы можем рассчитать среднеквадратичную ошибку (СКО) до любого разделения. Это также означает, что прогноз — это просто среднее значение y. СКО эквивалентна стандартному отклонению y.
Теперь идея состоит в том, чтобы найти такое разделение, чтобы среднеквадратическая ошибка (MSE) при таком разделении была ниже, чем раньше. Возможно, разделение не приведёт к значительному улучшению производительности (или снизит MSE), тогда итоговое дерево будет тривиальным, то есть средним значением y.
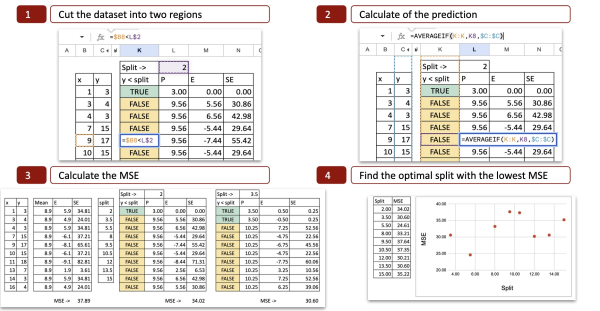
Для каждого возможного разделения мы можем рассчитать среднеквадратичную ошибку (MSE). На рисунке ниже показан расчёт для первого возможного разделения, которое равно x = 2.

Мы можем увидеть детали расчета:
- Разрезаем набор данных на две области: при значении x=2 определяем два возможных значения x<2 или x>2, поэтому ось x разрезается на две части.
- Рассчитаем прогноз: для каждой части вычисляем среднее значение y. Это и есть потенциальный прогноз для y.
- Рассчитаем ошибку: затем сравним прогноз с фактическим значением y
- Рассчитайте квадратичную ошибку: для каждого наблюдения мы можем вычислить квадратичную ошибку.

Оптимальное разделение
Для каждого возможного разделения мы делаем то же самое, чтобы получить среднеквадратичную ошибку (СКО). В Excel мы можем скопировать и вставить формулу, и единственное значение, которое изменится, — это возможное значение разделения для x.

Затем мы можем отобразить MSE на оси Y, а возможное разделение — на оси X. Теперь мы видим, что минимальное значение MSE достигается при x=5,5. Это именно тот результат, который получен с помощью кода Python.

Упражнение, которое вы можете попробовать
Теперь вы можете поиграться с Google Sheet:
- Вы можете изменить набор данных, MSE будет обновлена, и вы увидите оптимальный разрез.
- Вы можете ввести категориальный признак
- Вы можете попытаться найти следующий раздел.
- Вы можете изменить критерий, вместо MSE можно использовать абсолютную ошибку, Пуассона илиfriedman_mse, как указано в документации DecisionTreeRegressor.
- Вы можете изменить целевую переменную на бинарную. Обычно это становится задачей классификации, но 0 и 1 также являются числами, поэтому критерий MSE всё ещё можно применить. Но для создания корректного классификатора необходимо использовать обычный критерий Энтроя или Джини. Это тема следующей статьи.
Заключение
Используя Excel, можно реализовать одно разбиение, чтобы лучше понять, как работают регрессоры дерева решений. Хотя мы не создали полное дерево, это всё равно интересно, поскольку самое важное — найти оптимальное разбиение среди всех возможных.
Еще одна вещь
Заметили ли вы что-нибудь интересное в том, как обрабатываются характеристики между моделями, основанными на расстоянии, и деревьями решений?
В моделях, основанных на расстояниях, всё должно быть числовым. Непрерывные признаки остаются непрерывными, а категориальные признаки должны быть преобразованы в числа. Модель сравнивает точки в пространстве, поэтому всё должно отображаться на числовой оси.
Деревья решений делают обратное: они разделяют признаки на группы. Непрерывный признак становится интервальным. Категориальный признак остаётся категориальным.
А пропущенное значение? Оно просто становится другой категорией. Предварительно вводить данные не нужно. Дерево может справиться с этим естественным образом, отправив все «пропущенные» значения в одну ветвь, как и любую другую группу.
Источник: towardsdatascience.com