Изучение классификатора k-NN с его вариантами и усовершенствованиями
Делиться

После изучения регрессора k-NN и идеи прогнозирования на основе расстояния мы теперь рассмотрим классификатор k-NN.
Принцип тот же, но классификация позволяет нам ввести несколько полезных вариантов, таких как модель ближайших соседей по радиусу, модель ближайшего центроида, многоклассовое прогнозирование и вероятностные модели расстояний.
Поэтому сначала мы реализуем классификатор k-NN, а затем обсудим, как его можно улучшить.
Вы можете использовать эту таблицу Excel/Google при чтении статьи, чтобы лучше понять все объяснения.

Набор данных о выживании на «Титанике»
Мы будем использовать набор данных о выживании на «Титанике» — классический пример, где каждая строка описывает пассажира с такими характеристиками, как класс, пол, возраст и тариф, а цель — предсказать, выжил ли пассажир.

Принцип k-NN для классификации
Классификатор k-NN настолько похож на регрессор k-NN, что я мог бы написать одну статью, чтобы объяснить их оба.
На самом деле, когда мы ищем k ближайших соседей, мы вообще не используем значение y, не говоря уже о его природе.
НО есть еще несколько интересных фактов о том, как строятся классификаторы (бинарные или многоклассовые), и как можно по-разному обрабатывать признаки.
Начнем с задачи бинарной классификации, а затем перейдем к многоклассовой классификации.
Один непрерывный признак для двоичной классификации
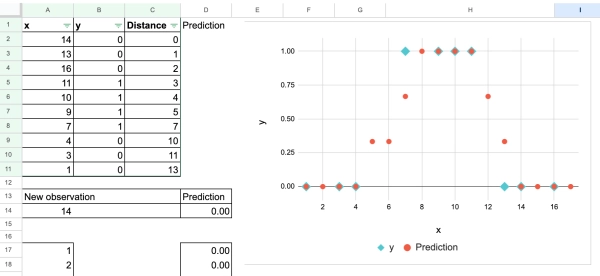
Итак, очень быстро мы можем проделать то же самое упражнение для одной непрерывной характеристики с этим набором данных.
Для значения y мы обычно используем 0 и 1, чтобы различать два класса. Но вы можете заметить, или заметите, что это может стать источником путаницы.

А теперь подумайте: 0 и 1 — это тоже числа, верно? Поэтому мы можем проделать тот же самый процесс, как при регрессии.
Всё верно. В расчётах ничего не меняется, как видно на следующем снимке экрана. И, конечно же, вы можете попробовать изменить значение нового наблюдения самостоятельно.

Единственное отличие заключается в том, как мы интерпретируем результат. Когда мы берём «среднее» значение y для соседей, это число понимается как вероятность того, что новое наблюдение принадлежит классу 1.
Таким образом, на самом деле «среднее» значение не является хорошей интерпретацией, а скорее представляет собой долю класса 1.
Мы также можем вручную создать этот график, чтобы показать, как прогнозируемая вероятность изменяется в диапазоне значений x.
Традиционно, чтобы избежать 50-процентной вероятности, мы выбираем нечетное значение k, чтобы всегда иметь возможность принять решение большинством голосов.

Двухфакторная бинарная классификация
Если у нас есть два признака, операция также почти такая же, как в регрессоре k-NN.

Одна функция для многоклассовой классификации
Теперь рассмотрим пример трех классов для целевой переменной y.
Тогда мы видим, что мы больше не можем использовать понятие «средний», поскольку число, представляющее категорию, на самом деле не является числом. И нам лучше называть их «категория 0», «категория 1» и «категория 2».

От k-NN до ближайших центроидов
Когда k становится слишком большим
Теперь давайте сделаем k большим. Насколько большим? Как можно больше.
Помните, мы также проделали это упражнение с регрессором k-NN и пришли к выводу, что если k равно общему числу наблюдений в обучающем наборе данных, то регрессор k-NN является простой оценкой среднего значения.
Для классификатора k-NN ситуация практически та же. Если k равно общему числу наблюдений, то для каждого класса мы получим его общую долю во всём обучающем наборе данных.
Некоторые люди, с байесовской точки зрения, называют эти пропорции априорными!
Но это не сильно помогает нам в классификации нового наблюдения, поскольку эти априорные данные одинаковы для каждой точки.
Создание центроидов
Итак, давайте сделаем еще один шаг.
Для каждого класса мы также можем сгруппировать все значения признаков x, принадлежащие этому классу, и вычислить их среднее значение.
Эти усредненные векторы признаков мы называем центроидами .
Что мы можем сделать с этими центроидами?
Мы можем использовать их для классификации нового наблюдения.
Вместо того чтобы пересчитывать расстояния до всего набора данных для каждой новой точки, мы просто измеряем расстояние до каждого центроида класса и присваиваем класс ближайшего из них.
Используя набор данных о выживании на «Титанике», мы можем начать с одной характеристики — возраста — и вычислить центроиды для двух классов: выживших пассажиров и невыживших пассажиров.

Теперь также можно использовать несколько непрерывных функций.
Например, мы можем использовать два признака: возраст и стоимость проезда.

И мы можем обсудить некоторые важные характеристики этой модели:
- Масштаб важен, как мы уже обсуждали ранее для регрессора k-NN.
- Пропущенные значения здесь не являются проблемой: когда мы вычисляем центроиды для каждого класса, каждый из них рассчитывается с использованием доступных (непустых) значений.
- Мы перешли от самой «сложной» и «большой» модели (в том смысле, что фактическая модель представляет собой весь обучающий набор данных, поэтому нам нужно хранить весь набор данных) к самой простой модели (мы используем только одно значение для каждого признака и храним только эти значения в качестве нашей модели).
От крайне нелинейного до наивно линейного
Но можете ли вы вспомнить хотя бы один существенный недостаток?
В то время как базовый классификатор k-NN является крайне нелинейным, метод ближайшего центроида является чрезвычайно линейным.
В этом одномерном примере два центроида — это просто средние значения x класса 0 и класса 1. Поскольку эти два средних значения близки, граница решения становится просто средней точкой между ними.
Таким образом, вместо кусочно-рваной границы, которая зависит от точного местоположения многих точек обучения (как в k-NN), мы получаем прямую границу, которая зависит только от двух чисел.
Это иллюстрирует, как метод ближайших центроидов сжимает весь набор данных в простое и очень линейное правило.

Замечание о регрессии: почему центроиды не применяются
Однако подобное улучшение невозможно для регрессора k-NN. Почему?
При классификации каждый класс образует группу наблюдений, поэтому вычисление среднего вектора признаков для каждого класса имеет смысл, и это дает нам центроиды классов.
Но в регрессии целевой y непрерывен. Нет ни дискретных групп, ни границ классов, и, следовательно, нет осмысленного способа вычисления «центроида класса».
Непрерывная цель имеет бесконечно много возможных значений, поэтому мы не можем сгруппировать наблюдения по их значению y для формирования центроидов.
Единственным возможным «центроидом» в регрессии было бы глобальное среднее , что соответствует случаю k = N в регрессоре k-NN.
И эта оценка слишком проста, чтобы быть полезной.
Короче говоря, классификатор ближайших центроидов является естественным улучшением для классификации, но у него нет прямого эквивалента в регрессии.
Дальнейшие статистические улучшения
Что еще мы можем сделать с базовым классификатором k-NN?
Среднее и дисперсия
В классификаторе ближайших центроидов мы использовали простейшую статистику — среднее значение . В статистике естественным рефлексом является добавление дисперсии .
Итак, теперь расстояние — это уже не евклидово, а расстояние Махаланобиса . Используя это расстояние, мы получаем вероятность, основанную на распределении, характеризуемом средним значением и дисперсией каждого класса.
Обработка категориальных характеристик
Для категориальных признаков мы не можем вычислить средние значения или дисперсии. Для регрессора k-NN мы увидели, что возможно прямое кодирование или порядковое кодирование/кодирование с метками. Но масштаб важен, и его непросто определить.
Здесь мы можем сделать нечто столь же значимое с точки зрения вероятностей: мы можем подсчитать доли каждой категории внутри класса .
Эти пропорции действуют точно так же, как вероятности, описывая, насколько вероятна каждая категория в каждом классе.
Эта идея напрямую связана с такими моделями, как категориальный наивный байесовский анализ , где классы характеризуются распределением частот по категориям.
Взвешенное расстояние
Другое направление — введение весов, чтобы более близкие соседи имели больший вес, чем дальние. В scikit-learn есть аргумент «весов», который позволяет это сделать.
Мы также можем переключиться с «k соседей» на фиксированный радиус вокруг нового наблюдения, что приводит к классификаторам на основе радиуса.
Радиус ближайших соседей
Иногда для пояснения работы классификатора k-NN можно встретить следующий рисунок. Но на самом деле, при таком радиусе он скорее отражает концепцию метода ближайших соседей.
Одним из преимуществ является контроль над окрестностями. Это особенно интересно, когда мы знаем конкретное значение расстояния, например, географическое.

Но недостаток в том, что радиус нужно знать заранее.
Кстати, это понятие радиуса ближайших соседей также подходит для регрессии.
Обзор различных вариантов
Все эти небольшие изменения дают разные модели, каждая из которых пытается улучшить базовую идею сравнения соседей в соответствии с более сложным определением расстояния, с контрольным параметром, который позволяет нам получать локальных соседей или более глобальную характеристику соседства.
Мы не будем здесь рассматривать все эти модели. Я просто не могу удержаться от того, чтобы не зайти слишком далеко, когда небольшое изменение естественным образом приводит к другой идее.
На данный момент рассматривайте это как анонс моделей, которые мы реализуем в конце этого месяца.

Заключение
В этой статье мы рассмотрели классификатор k-NN от его самой базовой формы до нескольких расширений.
Основная идея по сути не меняется: новое наблюдение классифицируется на основе проверки того, насколько оно похоже на обучающие данные.
Но эта простая идея может принимать самые разные формы.
В случае непрерывных признаков сходство основывается на геометрическом расстоянии.
При использовании категориальных признаков мы смотрим на то, как часто каждая категория встречается среди соседей.
Когда k становится очень большим, весь набор данных сворачивается всего в несколько сводных статистик, что естественным образом приводит к классификатору ближайших центроидов .
Понимание этого семейства идей, основанных на расстоянии и вероятности, помогает нам увидеть, что многие модели машинного обучения — это просто разные способы ответа на один и тот же вопрос:
К какому классу больше всего похоже это новое наблюдение?
В следующих статьях мы продолжим изучение моделей на основе плотности, которые можно понимать как глобальные меры сходства между наблюдениями и классами.
Источник: towardsdatascience.com