Узнайте, как простая формула расстояния становится прогностической моделью, шаг за шагом в Excel
Делиться

Добро пожаловать в этот «Рождественский календарь» машинного обучения и глубокого обучения в Excel.
В первый день мы начнём с алгоритма регрессора k-NN (k-ближайших соседей). Как вы увидите, это действительно самая простая модель, и она отлично подойдёт для начала.
Для тех, кто уже знаком с этой моделью, вот несколько вопросов. Надеюсь, они заставят вас продолжить чтение. Кроме того, есть несколько тонких уроков, которые не преподаются в традиционных курсах.
- Важно ли масштабирование непрерывных признаков для этой модели?
- Как можно обрабатывать категориальные признаки?
- Что следует сделать с непрерывными функциями, чтобы улучшить производительность модели?
- Какие типы измерения расстояния могут быть более подходящими в определённых ситуациях? Например, при прогнозировании цен на жильё, где географическое положение имеет значение?
Спойлер: с помощью наивного k-NN вы не сможете автоматически получить идеальное масштабирование.
Это также возможность, если вы не знакомы с формулами Excel, использовать такие формулы, как РАНГ, ЕСЛИ, СУММПРОИЗВ и другие полезные функции Excel.
Вы можете воспользоваться этой ссылкой, чтобы получить файл Excel/Google Sheets, и я советую вам ознакомиться со статьей и провести небольшое тестирование файла, чтобы лучше понять его.

Принцип k-NN
Если вы хотите продать или купить квартиру, как бы вы оценили цену?
Пожалуйста, подумайте о реалистичном подходе, а не о какой-то сложной модели, на построение которой вам придется потратить часы.
Что-то, что вы можете сделать по-настоящему.
Ну, вы, вероятно, спросите у соседей, у которых есть квартиры такой же или похожей площади. И посчитаете среднюю стоимость этих квартир.
Да, именно в этом и заключается идея k-NN (k-ближайших соседей): поиск наиболее похожих примеров и использование их значений для оценки нового.
Чтобы проиллюстрировать эту задачу на конкретном примере оценки стоимости жилья, мы воспользуемся известным набором данных California Housing Dataset. Это данные переписи населения, полученные в жилых кварталах Калифорнии, которые используются для прогнозирования медианной стоимости жилья .

Каждое наблюдение не является отдельным домом, но все равно интересно использовать этот пример.
Вот краткое описание переменных.
Целевая переменная — MedHouseVal , которая представляет собой медианную стоимость дома в единицах по 100 000 долларов США (пример: 3,2 означает 320 000 долларов).
Переменные признаков следующие:
1. MedInc : медианный доход (в единицах по 10 000 долларов США)
2. HouseAge : средний возраст домов
3. AveRooms : среднее количество комнат в домохозяйстве.
4. AveBedrms : среднее количество спален в домохозяйстве.
5. Население : люди, проживающие в квартале
6. AveOccup : среднее количество жильцов в домохозяйстве
7. Широта : географическая широта
8. Долгота : географическая долгота
k-NN с одним непрерывным признаком
Прежде чем использовать несколько признаков для поиска соседей, давайте сначала воспользуемся только одним признаком и несколькими наблюдениями.
Несмотря на то, что процесс для одного непрерывного признака будет очень простым, мы всё равно будем следовать каждому шагу. Сначала мы исследуем наш набор данных, затем обучаем модель с помощью гиперпараметра, и, наконец, можем использовать модель для прогнозирования.
Набор обучающих данных
Вот график этого простого набора данных из 10 наблюдений. Ось X — непрерывная характеристика, ось Y — целевая переменная.

Теперь представьте, что нам нужно предсказать значение нового наблюдения x = 10. Как это сделать?
Обучение на моделях?
Первым шагом практически всех моделей машинного обучения является обучение.
Но для k-NN ваша модель — это весь ваш набор данных. Другими словами, вам не нужно обучать модель, вы используете исходный набор данных напрямую.
Таким образом, в scikit-learn при выполнении model.fit для оценки k-NN на самом деле ничего не происходит.
Некоторые могут спросить: а как насчет k?
Итак, k — это гиперпараметр. Поэтому вам нужно выбрать значение k, которое можно настроить.
Прогноз для одного нового наблюдения
Для гиперпараметра k мы будем использовать k=3, поскольку набор данных очень мал.
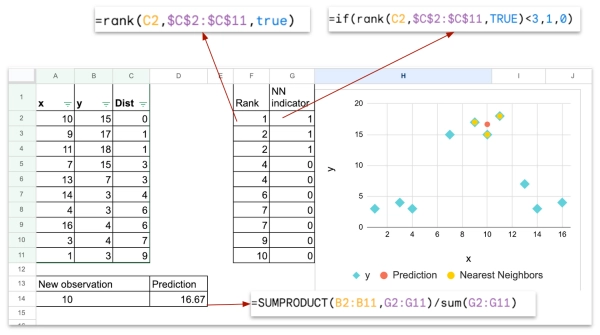
Для одной переменной-признака расстояние может быть тривиальным абсолютным значением разницы между значением нового наблюдения и другими.
На листе «algo1D» можно изменить значение нового наблюдения и использовать фильтр по столбцу расстояния C, чтобы упорядочить набор данных в порядке возрастания; будут отображены 3 ближайших соседа.
Чтобы сделать расчет более автоматическим, мы можем использовать функцию RANK, чтобы увидеть наименьшие наблюдения с точки зрения расстояния.
И мы также можем создать столбец индикаторов (столбец G), с индикатором = 1, если они принадлежат k-ближайшим соседям.
Наконец, для прогнозирования мы можем использовать функцию СУММПРОИЗВ для вычисления среднего значения всех значений y с индикатором =1.
В сюжете,
- светло-голубые точки представляют набор данных
- красная точка представляет новое наблюдение с предсказанным значением y
- желтые точки представляют трех ближайших соседей нового наблюдения (красного цвета)

Подведем итоги — фаза прогнозирования состоит из следующих этапов:
- Для одного заданного нового наблюдения вычислите расстояние между этим новым наблюдением и всеми наблюдениями в обучающем наборе данных.
- Определим k наблюдений с наименьшим расстоянием. В Excel мы воспользуемся фильтром для ручного упорядочивания обучающего набора данных. Или можем использовать функцию RANK (и столбец индикатора) для получения k первых наблюдений.
- Рассчитайте прогнозируемое значение, вычислив среднее значение целевой переменной с помощью функции СУММПРОИЗВ.
Прогноз на интервал новых наблюдений
На листе «algo1D f» (f — final) я построил прогноз для списка новых наблюдений в диапазоне от 1 до 17.
Используя язык программирования, мы могли бы легко сделать это в цикле и для большего количества новых наблюдений, поэтому представление могло бы быть более плотным.
В Excel я вручную повторил следующие шаги:
- введите значение для x
- упорядочить столбец расстояний
- скопируйте и вставьте прогноз

Влияние гиперпараметра k
Гиперпараметр, используемый в k-NN, — это количество соседей, которое мы учитываем при расчете среднего значения.
Обычно мы используем следующий график, чтобы объяснить, как модель может быть недообучена или переобучена.

В нашем случае, если k мало, может возникнуть риск переобучения.
Если k велико, может возникнуть риск недообучения.
Крайний случай очень большого k — это когда k может быть равен общему числу элементов обучающего набора данных. При этом значение прогноза будет одинаковым для каждого нового наблюдения: это глобальное среднее значение.

Таким образом, можно сказать, что k-NN улучшает идею прогнозирования посредством вычисления среднего значения по нескольким наблюдениям, близким к новому наблюдению.
k-NN с двумя непрерывными признаками
Теперь мы рассмотрим случай двух непрерывных признаков x1 и x2. Мы обсудим только различия с предыдущей ситуацией с одним признаком.
Набор данных с двумя непрерывными переменными признаков
Когда у нас есть две переменные-характеристики, я не могу построить трехмерный график в Excel, поэтому график содержит только x1 в качестве оси x и x2 в качестве оси y.
Поэтому не путайте его с предыдущим набором данных, в котором ось Y представляет собой целевое значение y.

Прогнозирование с использованием евклидова расстояния
Теперь, когда у нас есть две особенности, нам придется учитывать их обе.
Одно из расстояний, которое мы обычно можем использовать, — это евклидово расстояние.
Затем мы можем применить тот же процесс к k первым наблюдениям, имеющим минимальное расстояние с новым наблюдением.

Чтобы получить визуальный сюжет, мы можем использовать те же цвета
- Синий — для обучающего набора данных
- Красный — для нового наблюдения
- Желтый для найденных k ближайших соседей

Влияние масштаба переменных
Когда у вас есть две характеристики, один из вопросов, который мы можем задать, — это влияние масштаба характеристики на результат прогнозирования.
Для начала давайте рассмотрим простой пример: я умножил признак x2 на 10.

Повлияет ли это масштабирование на прогнозы? Ответ, конечно, да.
И мы можем легко их сравнить, как на следующем изображении.

Достаточно легко понять, что евклидово расстояние представляет собой сумму квадратов разностей характеристик, независимо от их масштабов.
В результате объект, имеющий больший масштаб, будет доминировать на расстоянии.
При масштабировании признаков часто применяется стандартизация (также называемая центрированием и редукцией) или масштабирование по минимуму и максимуму. Идея заключается в том, чтобы привести все признаки к сопоставимому масштабу.
НО давайте подумаем о такой ситуации: что, если одна характеристика выражена в долларах, а другая в иенах.
В реальном мире правильное соотношение между двумя шкалами составляет примерно 1 доллар = 156 иен (по состоянию на ноябрь 2025 года). Мы знаем это, потому что понимаем значение единиц.
Откуда модель это знает? Она НЕ ЗНАЕТ.
Единственным гиперпараметром является k, и модель не корректирует ничего для коррекции различий в единицах измерения или масштабах. У k-NN нет внутреннего механизма для понимания того, что два объекта имеют разные единицы измерения.
И это только начало проблем…
k-NN с набором данных о жилищном строительстве в Калифорнии
Теперь давайте наконец воспользуемся реальным набором данных California Housing.
На примере однопризнакового набора данных мы получили базовое представление о работе k-NN. На примере двухпризнакового набора данных мы увидели, что масштаб признаков важен.
Теперь, с этим реальным набором данных, мы увидим, что неоднородная природа объектов делает евклидово расстояние бессмысленным.
Мы увидим еще несколько важных идей, когда будем использовать k-NN на практике.
Наивное применение регрессора k-NN
Поскольку все признаки в этом наборе данных непрерывны, мы можем легко вычислить евклидово расстояние. Мы также определяем число k для вычисления среднего значения целевой переменной, в данном случае MedHouseVal.
В Excel вы легко можете сделать это самостоятельно. Или можете поддержать меня здесь и получить все файлы.

Понятие расстояния, основанное на различных признаках
Я сказал, что предыдущее приложение наивно, потому что если вы посмотрите внимательнее, то увидите следующие проблемы:
Медианный доход (MedInc) выражается в единицах по 10 000 долларов США. Если мы решим выразить его в 100 000 долларов США или в 1000 долларов США, прогноз изменится, поскольку k-NN чувствителен к масштабу признаков. Мы уже сталкивались с этой проблемой.
Теперь, более того, каждая особенность имеет разную природу.
- MedInc — это сумма денег (в долларах).
- HouseAge — возраст в годах.
- AveRooms — количество комнат.
- Население — это число людей.
- Широта и долгота — географические координаты.
Следовательно, евклидово расстояние обречено.
Различные типы расстояний
Наиболее распространенным выбором является евклидово расстояние, но это не единственный вариант.
Мы также можем использовать манхэттенское расстояние , когда признаки представляют собой движения в виде сетки, и косинусное расстояние, когда имеет значение только направление (как в случае встраивания текста).
Каждое расстояние меняет определение «ближайшего» и, следовательно, может влиять на то, каких соседей выбирает KNN.
В зависимости от данных могут быть более подходящими другие расстояния.
Например, в случае широты и долготы мы можем использовать реальное географическое расстояние (в метрах) вместо простого евклидова расстояния в градусах.
В наборе данных о жилищном строительстве Калифорнии это особенно полезно, поскольку у нас есть точная широта и долгота каждого района.
Однако как только мы пытаемся объединить эти географические расстояния с другими переменными (такими как средний доход, количество комнат или численность населения), проблема становится более сложной, поскольку переменные имеют совершенно разную природу и масштабы.

В картографических визуализациях ниже я использовал k-NN в качестве сглаживающей функции для уточнения значений, связанных с различными районами Парижа.
Слева каждая область имеет только одно значение, поэтому от одной четверти к соседним четвертям может наблюдаться разрыв переменной.
Справа k-NN позволяет мне оценить значение для каждого конкретного адреса, сглаживая информацию на основе близлежащих областей.
Более того, для таких показателей, как доля определенных профессиональных категорий, я также применил взвешивание на основе численности населения, чтобы более крупные территории оказывали более сильное влияние на процесс сглаживания.

В заключение следует сказать, что, когда ситуация позволяет, выбор более конкретной дистанции может помочь нам лучше уловить лежащую в основе реальность.
Связывая расстояние с природой данных, мы можем сделать k-NN гораздо более осмысленным: географическое расстояние для координат, косинусное расстояние для векторных представлений и т. д. Выбор расстояния — это не просто техническая деталь, он меняет то, как модель «видит» мир и какие соседи она считает релевантными.
Как можно моделировать категориальные признаки
Вы могли слышать, что категориальные признаки не могут быть обработаны в моделях k-NN.
Но это не совсем так.
k-NN может работать с категориальными переменными, если мы можем определить расстояние между двумя наблюдениями.
Многие скажут: «Просто используйте прямое кодирование».
Другие упоминают кодирование меток или порядковое кодирование.
Однако в модели, основанной на расстоянии, эти методы ведут себя совершенно иначе.
Чтобы прояснить это, мы воспользуемся другим набором данных: набором данных о ценах на бриллианты (лицензия CC BY 4.0), который содержит несколько характеристик, таких как каратность, огранка, цвет и чистота.
Для простоты мы будем использовать только караты (числовую величину) и чистоту (категориальную величину), чтобы продемонстрировать несколько результатов.
Прогнозирование цен с помощью Carat
Начнем с карат , поскольку вы, вероятно, знаете, что цена бриллианта зависит в основном от размера (каратности) камня.
На графике ниже показано, как k-NN может находить бриллианты схожих размеров, чтобы оценить их цену.

Функция One-Hot Encoding for Clarity
Теперь давайте посмотрим на ясность .
Ниже приведена таблица категорий с их значениями, и мы применяем прямое кодирование для преобразования каждой категории в двоичный вектор.
| Ясность | Значение |
| ЕСЛИ | Внутренне безупречный |
| ВВС1 | Очень очень немного включено 1 |
| ВВС2 | Очень-очень слабо включено 2 |
| ВС1 | Очень слабо включено 1 |
| ВС2 | Очень слабо включено 2 |
| СИ1 | Слегка включено 1 |
| СИ2 | Слегка включено 2 |
| И1 | Включено 1 |
В этой таблице мы видим, что для нового бриллианта с чистотой VVS2 ближайшими соседями являются все бриллианты той же категории чистоты .
Числовая характеристика карат оказывает очень малое влияние на расстояние, хотя она является более важной характеристикой, как вы можете видеть в колонке цены.

Ключевая проблема 1: все категории одинаково далеки
При использовании евклидова расстояния для однонаправленных векторов:
- ЕСЛИ против VVS1 → расстояние = √2
- ЕСЛИ против SI2 → расстояние = √2
- ЕСЛИ против I1 → расстояние = √2
Каждая отдельная категория находится на совершенно одинаковом расстоянии.
Это не отражает реальную шкалу оценки алмазов.
Ключевая проблема 2: проблема масштабирования с непрерывными переменными
Поскольку мы объединяем чистоту одного бриллианта с каратностью (непрерывной характеристикой), мы сталкиваемся с другой проблемой:
- В нашем примере значения карат ниже 1
- Векторы ясности имеют разность √2 → ясность доминирует при расчете расстояния
Поэтому даже небольшие изменения в чистоте перевешивают эффект от каратности.
Это точно такая же проблема масштабирования, с которой мы сталкиваемся при работе с многонепрерывными объектами, но даже более сильная.
Порядковое кодирование для ясности
Теперь мы можем попробовать закодировать признак «Чёткость» с помощью числовых меток. Но вместо классических меток 1, 2, 3… мы используем экспертные метки , отражающие реальную шкалу оценок.
Идея состоит в том, чтобы перевести уровни чистоты в значения, которые ведут себя скорее как непрерывная характеристика, подобная каратам, даже если чистота не является строго непрерывной.

Благодаря этому экспертному кодированию расстояния становятся более значимыми.
Каратность и чистота теперь находятся на сопоставимых шкалах, поэтому ни одна из характеристик не имеет решающего значения при расчете расстояния.
Таким образом, мы получаем лучший баланс между размером и четкостью при выборе соседей, что дает более реалистичные прогнозы.

Выводы
В заключение отметим, что регрессор k-NN — это крайне нелинейный локальный оценщик. Он настолько локален, что фактически используются только K ближайших наблюдений.
После внедрения регрессора k-NN в Excel, я думаю, мы действительно можем задать этот вопрос: является ли регрессор k-NN на самом деле моделью машинного обучения?
- Нет никакого модельного обучения
- При прогнозировании выбор соседних наблюдений не зависит от значения целевой переменной.
Но это настолько просто, что с помощью Excel мы можем просто реализовать весь алгоритм. Более того, мы можем регулировать расстояние по своему усмотрению.
Бизнесмены могут увидеть эту идею напрямую: чтобы предсказать значение, мы смотрим на аналогичные наблюдения.
Фактические проблемы с k-NN и всеми моделями, основанными на расстоянии:
- масштаб особенностей
- неоднородность характеристик, что делает сумму бессмысленной
- конкретное расстояние, которое следует определить в конкретных ситуациях
- Для категориальных признаков меточное/порядковое кодирование можно было бы оптимизировать, если бы удалось найти оптимальное масштабирование.
Итак, короче говоря, проблема заключается в масштабировании признаков. Мы могли бы подумать, что их можно настроить как гиперпараметры, но тогда такая настройка потребует слишком много времени.
Позже мы увидим, что именно эта мотивация лежит в основе другого семейства моделей.
Здесь понятие масштаба также эквивалентно понятию важности признаков, поскольку в k-NN важность каждого признака определяется до использования модели.
Итак, это только начало нашего пути. Мы вместе найдём другие модели, которые могут быть лучше этой простой модели, совершенствуя её в разных направлениях: масштабирование признаков, переход от расстояния к вероятности, разделение для лучшего моделирования каждой категории…
Источник: towardsdatascience.com